采集插件
介绍
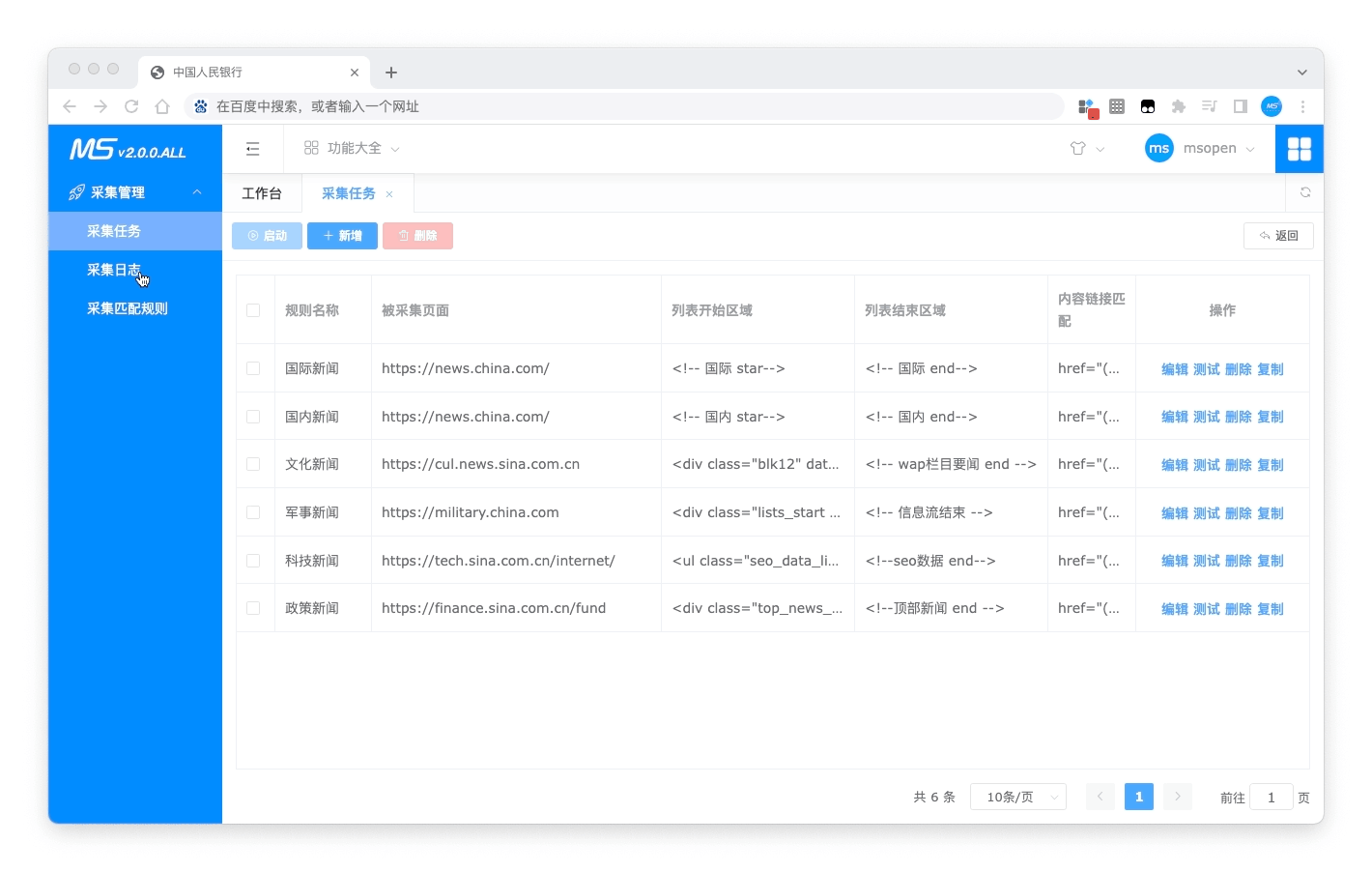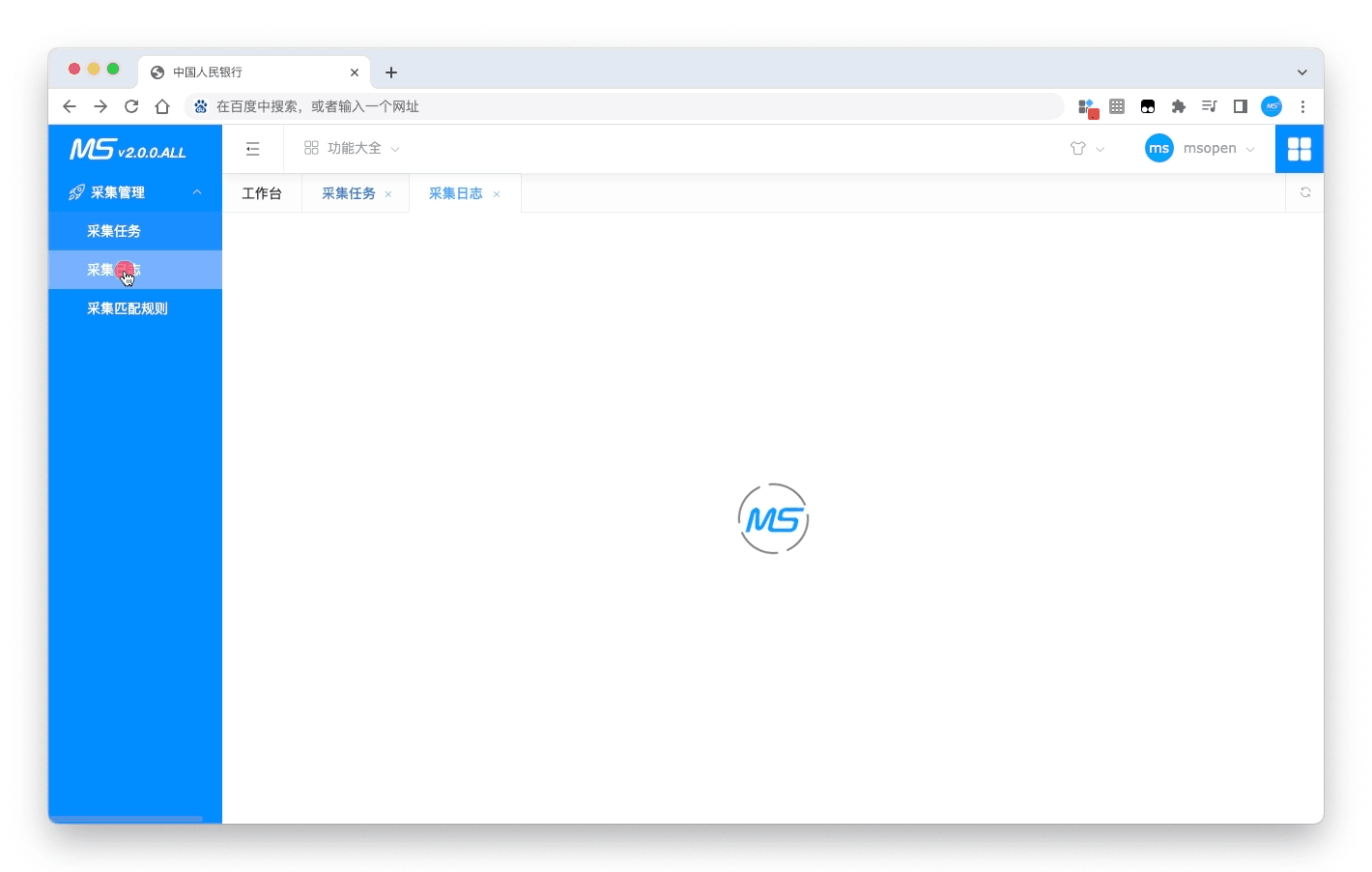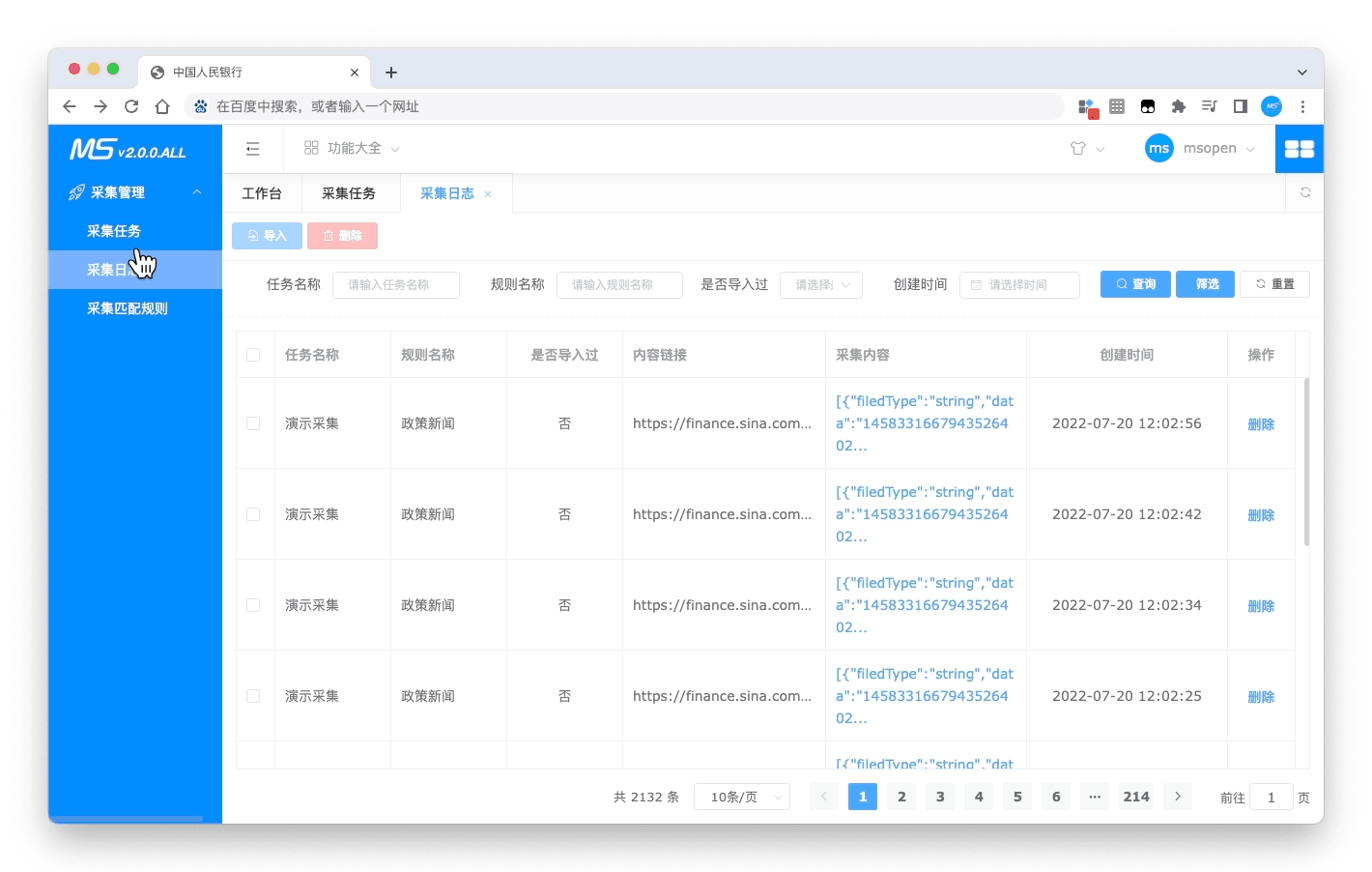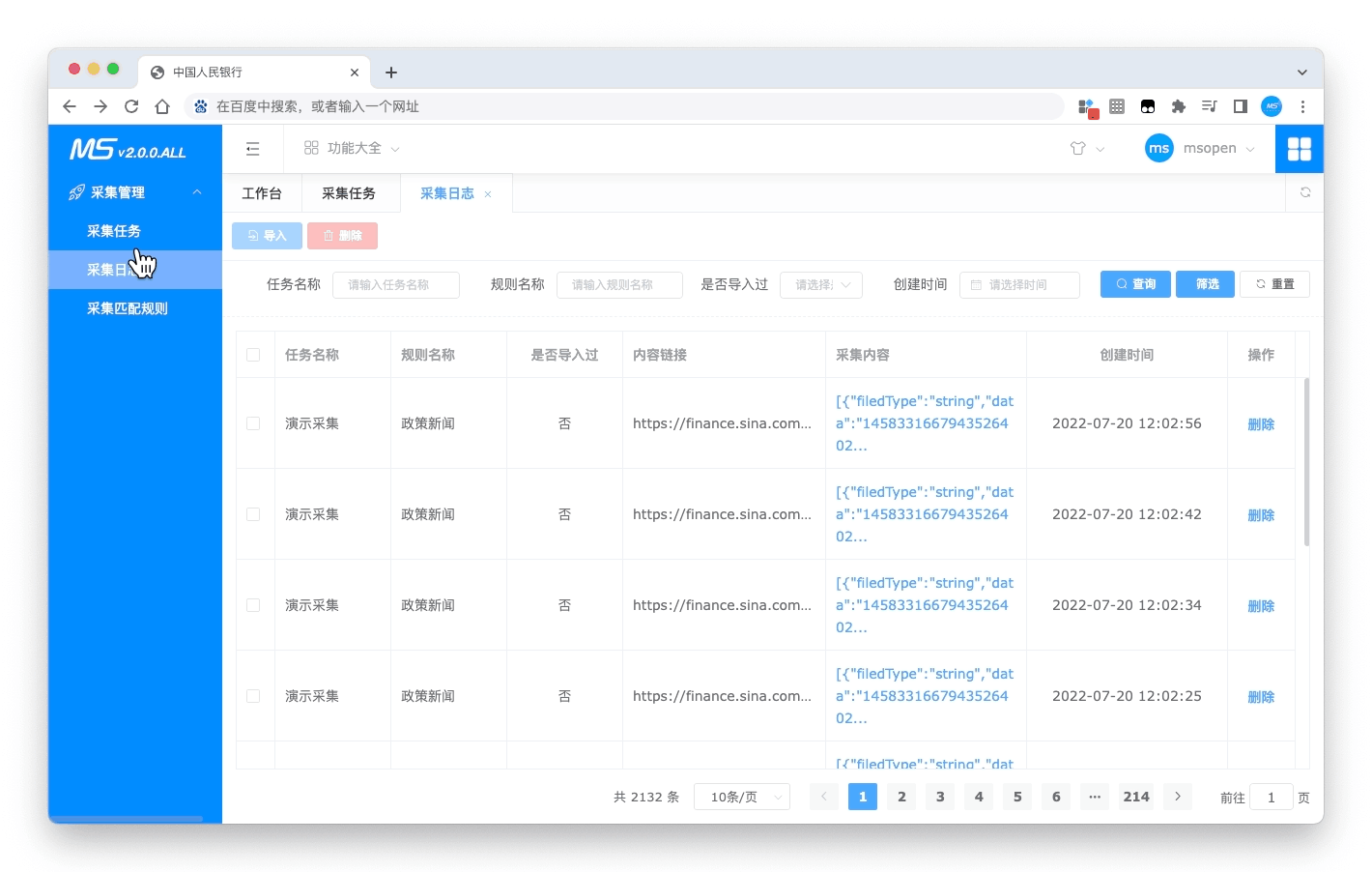
包含采集任务、采集规则、采集日志、导入数据、自动导入等功能
依赖
<dependency>
<groupId>net.mingsoft</groupId>
<artifactId>ms-spider</artifactId>
<version>当前版本</version>
</dependency>
依赖 webmagic-core 开源项目 感谢 https://github.com/code4craft/webmagic
动图展示
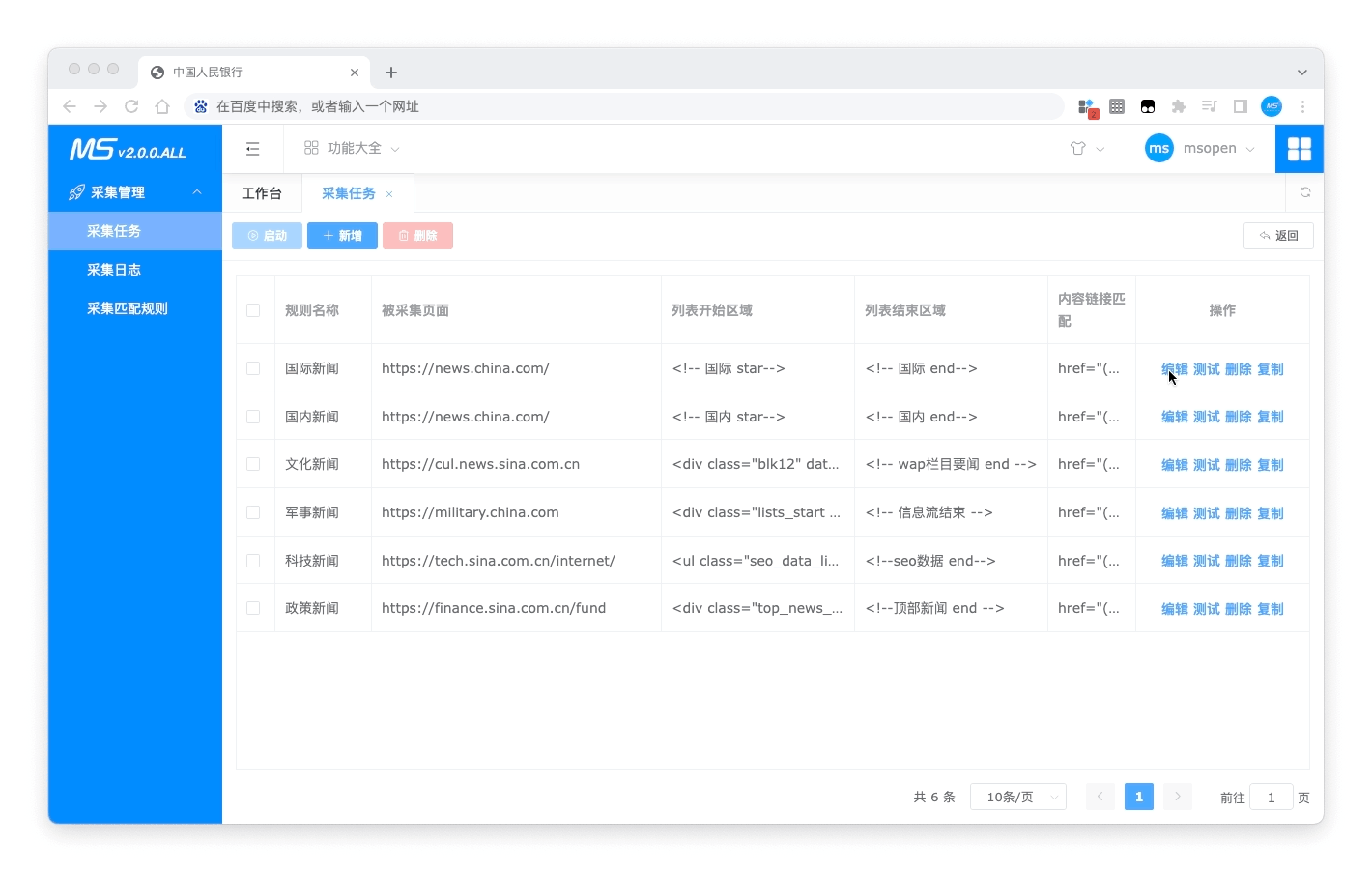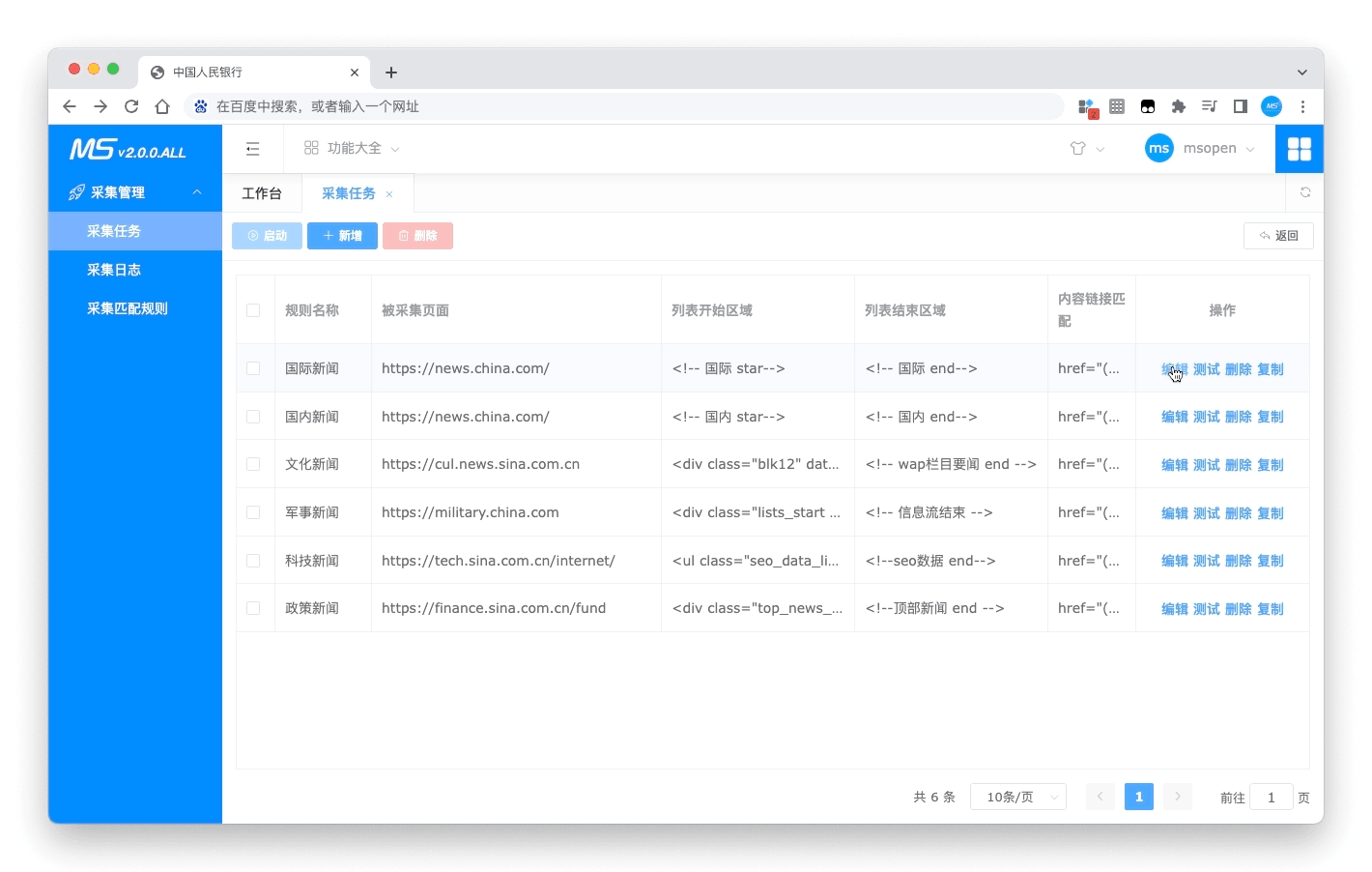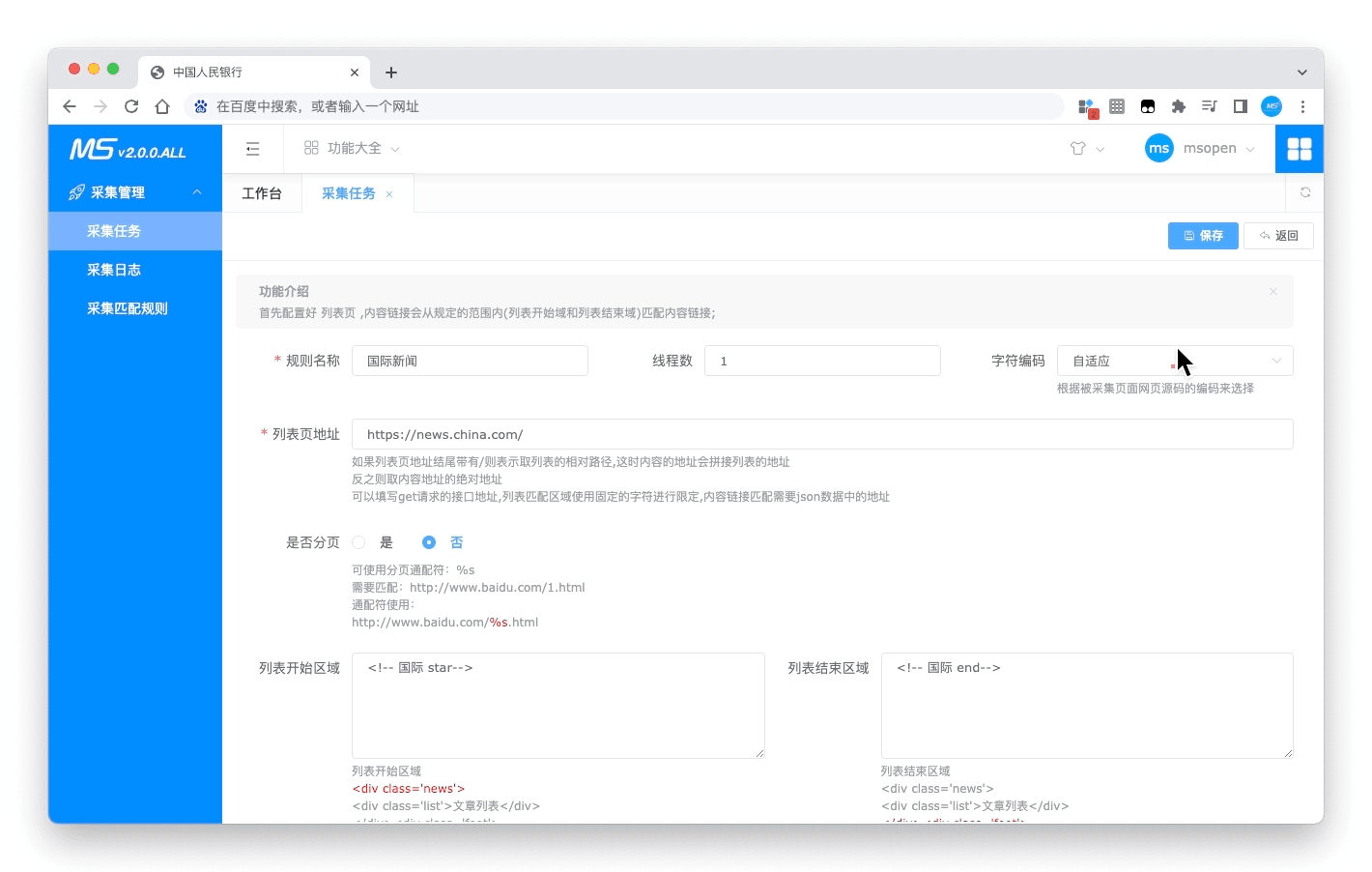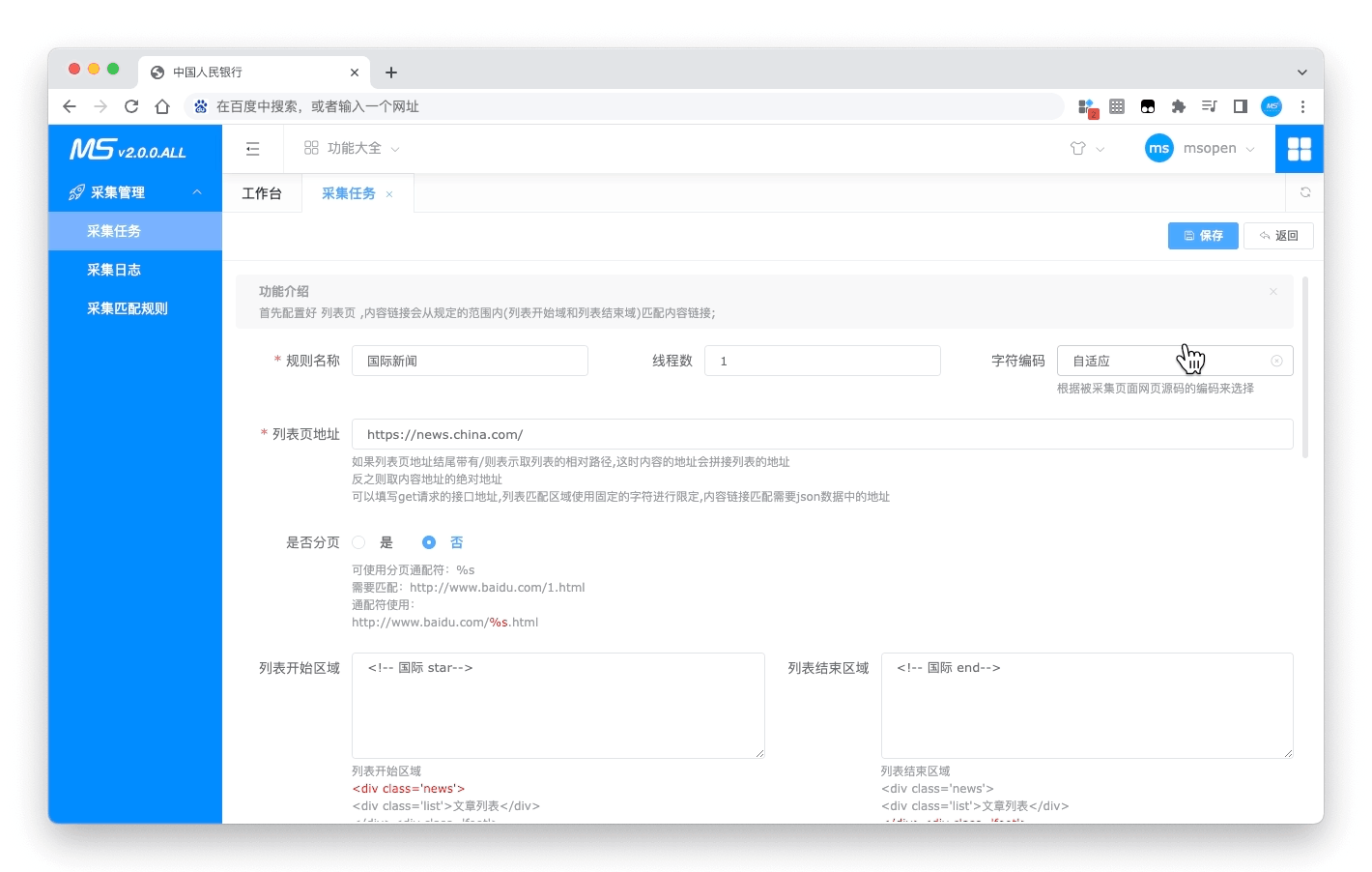
- 创建采集
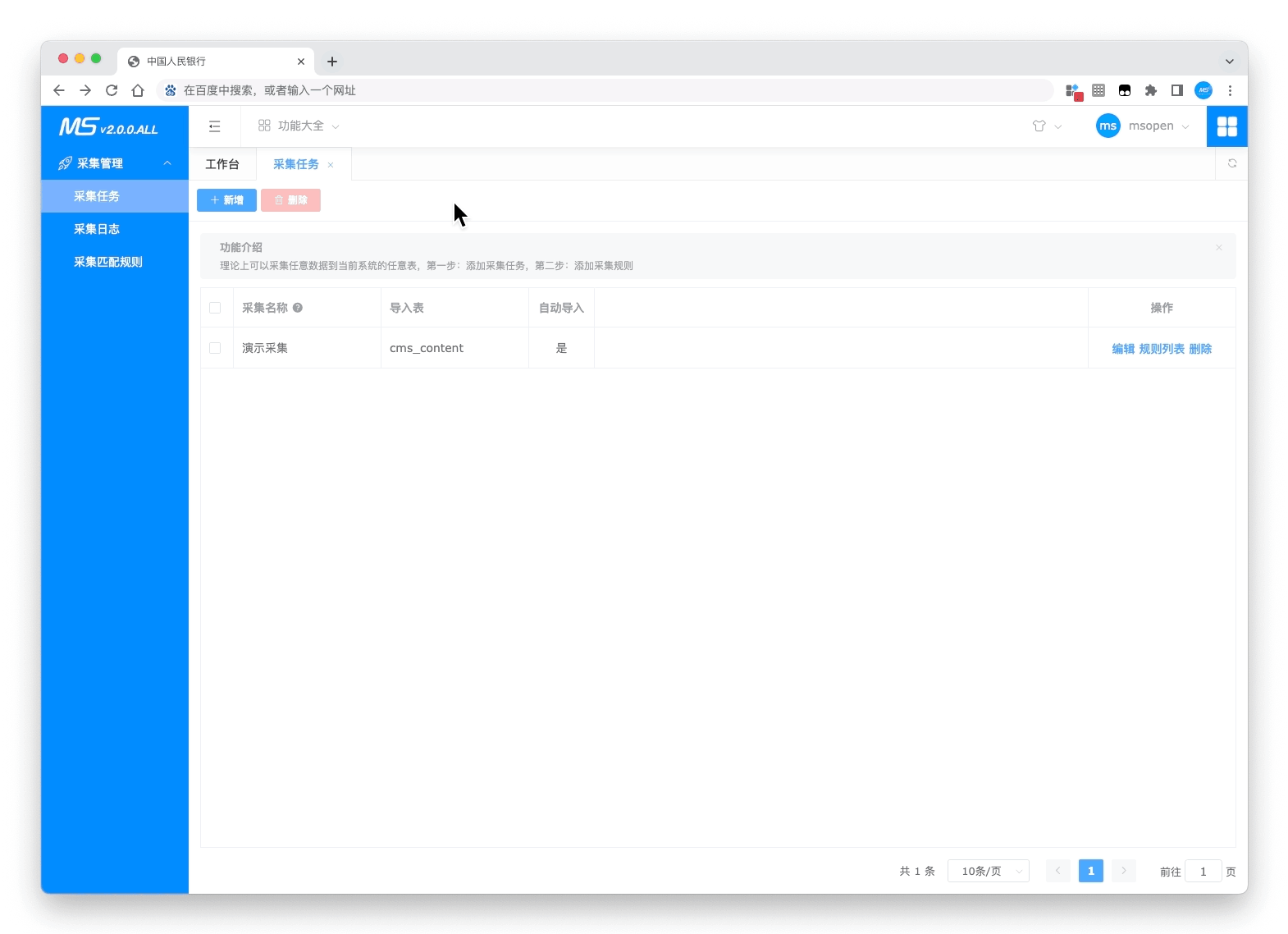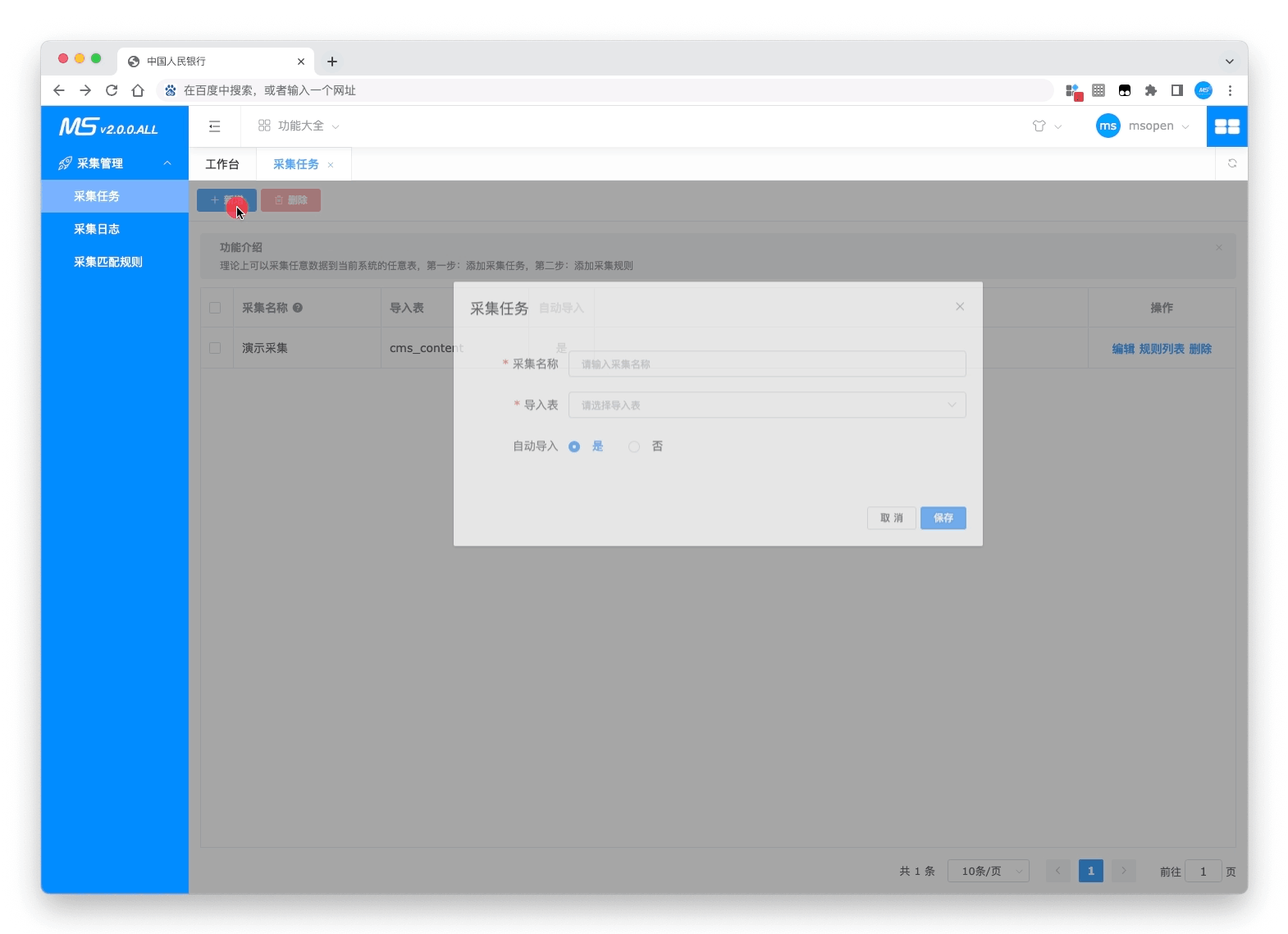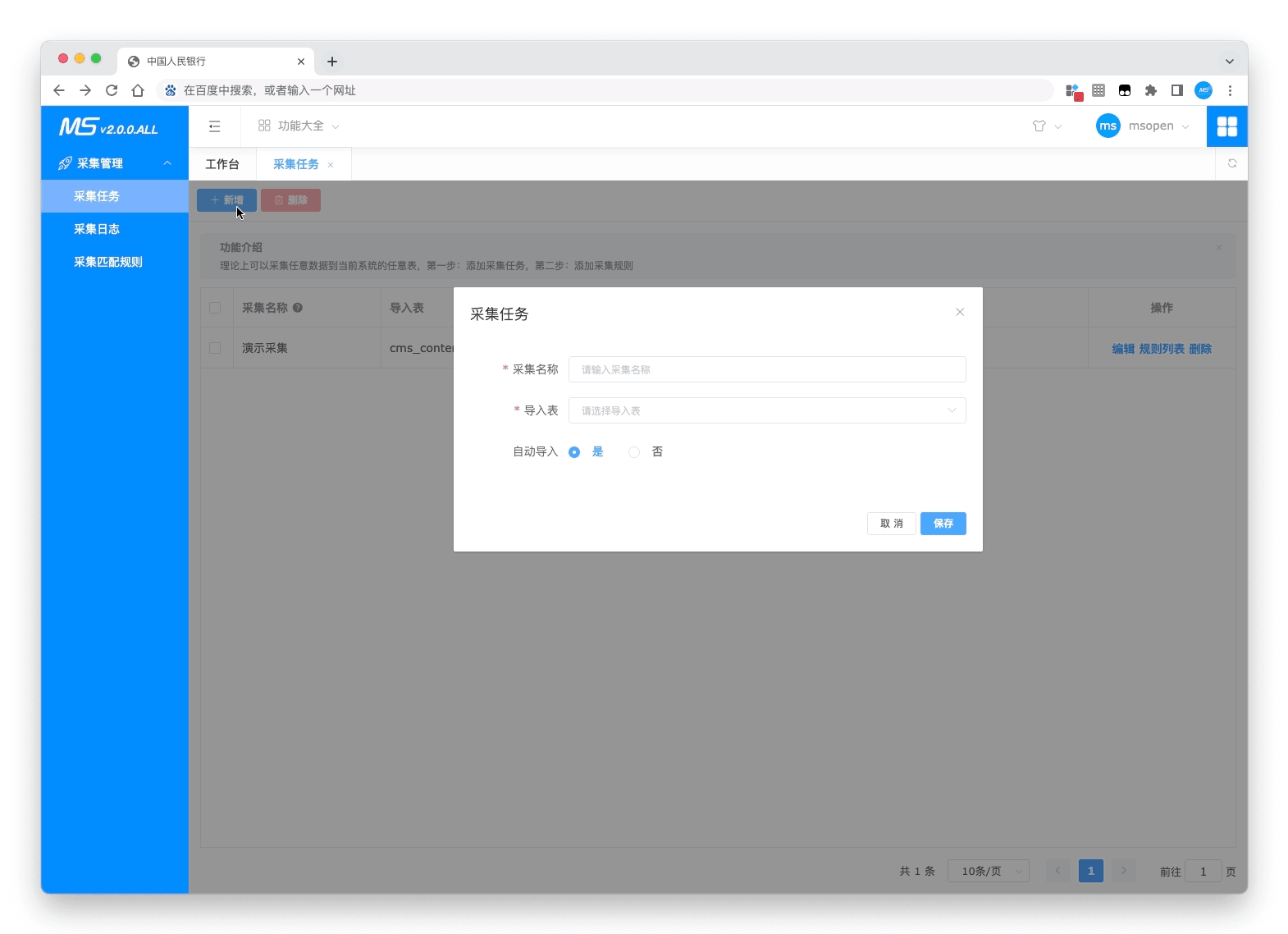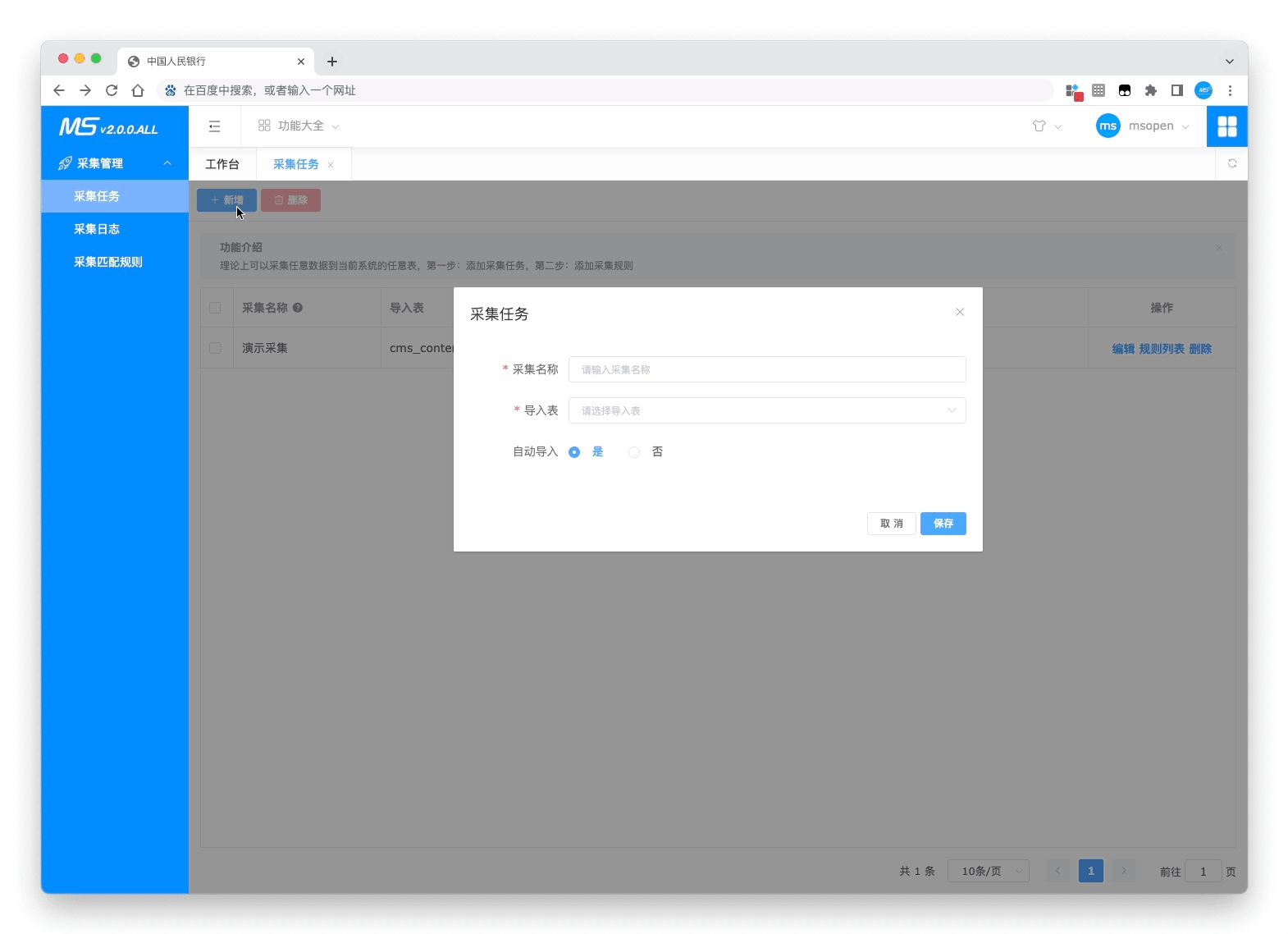
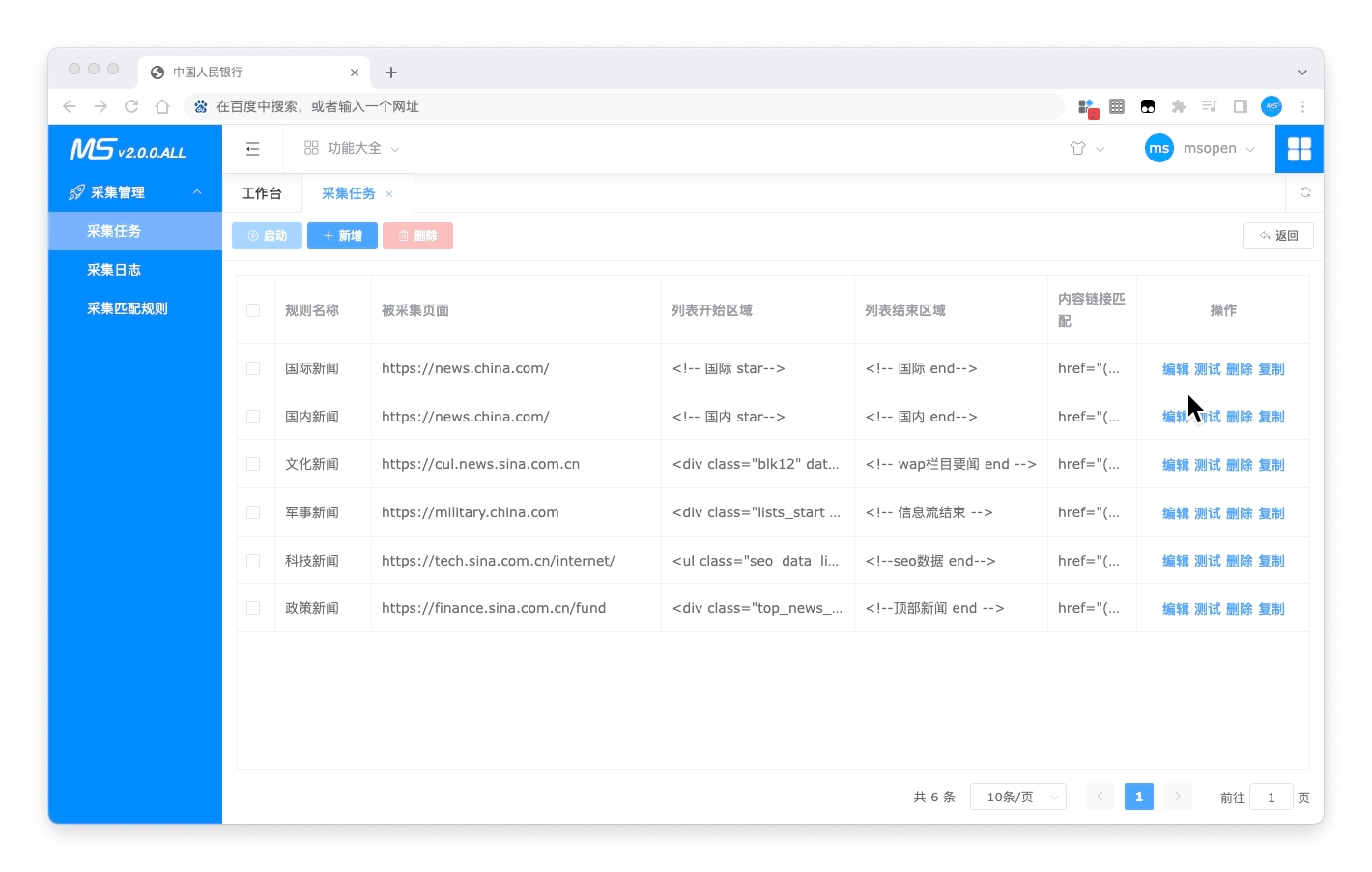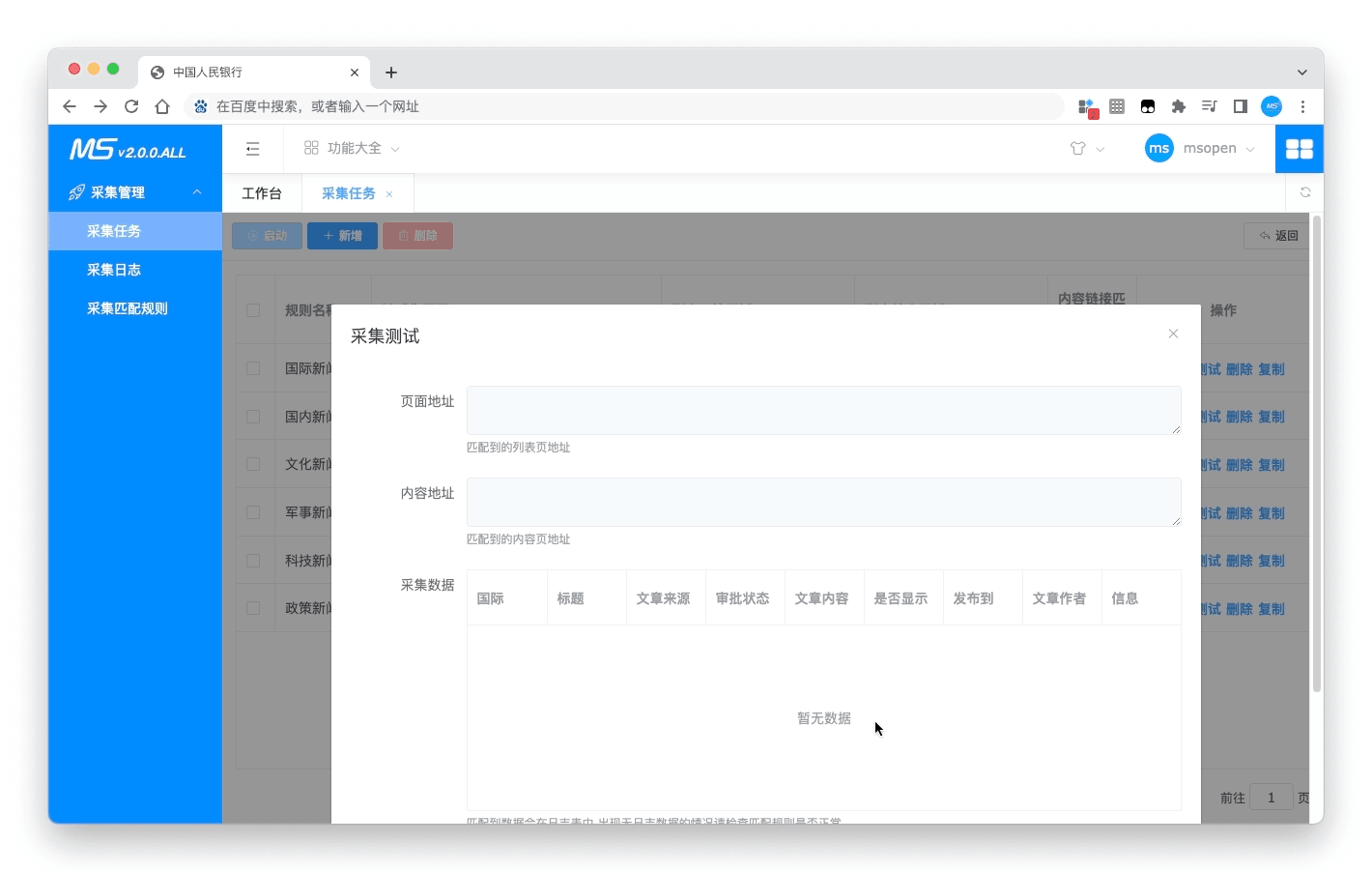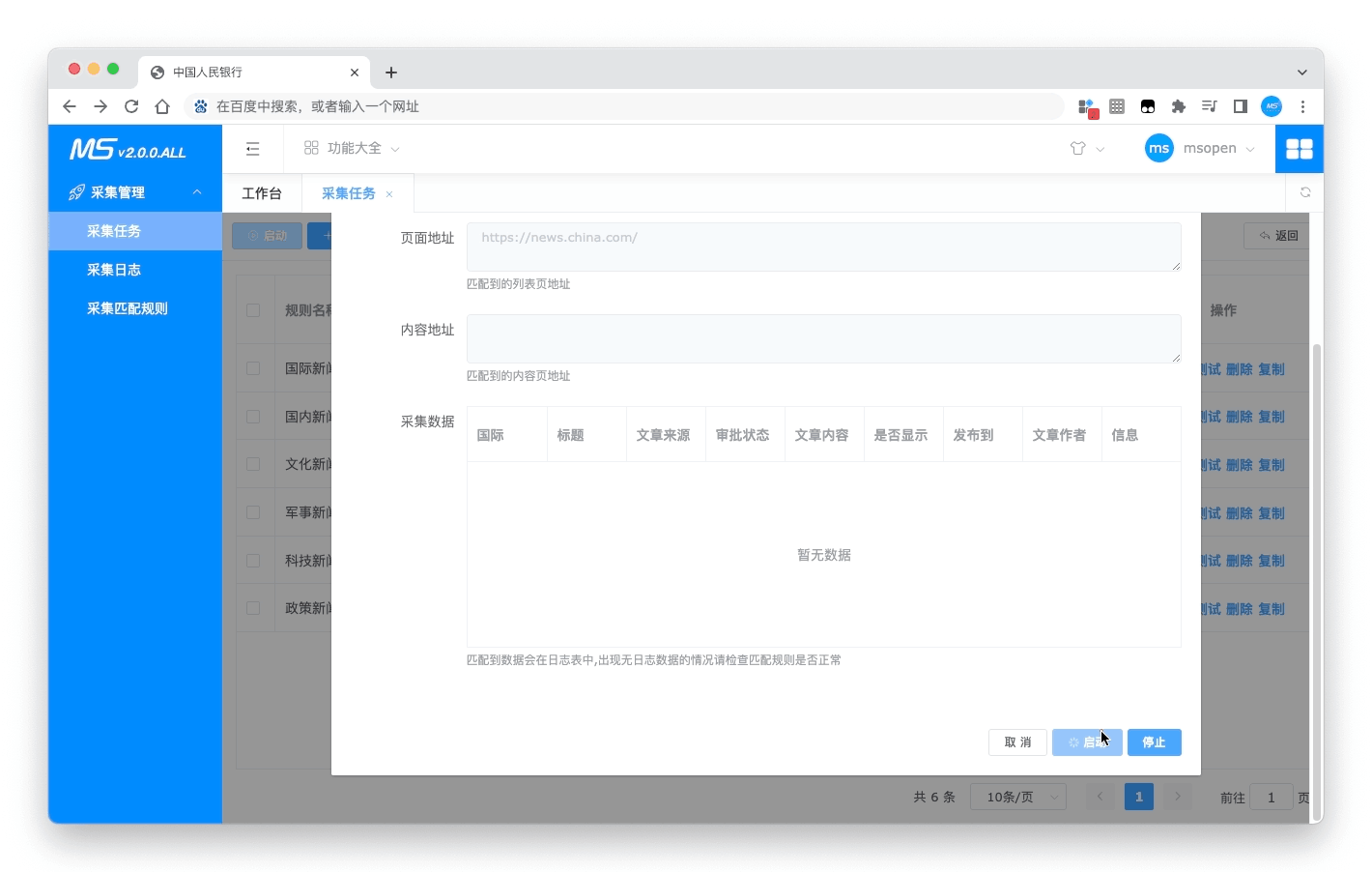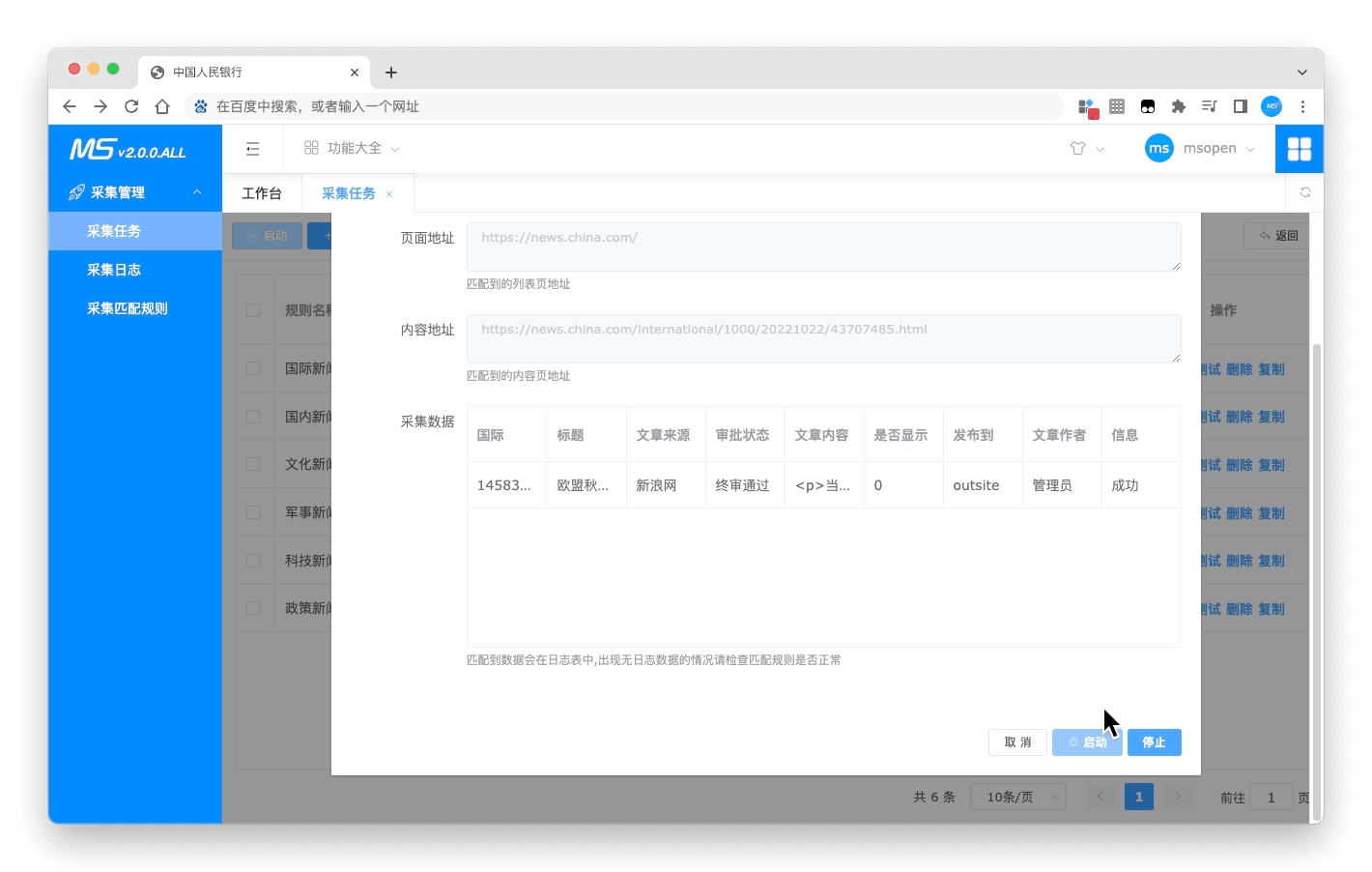
- 测试采集
- 编辑采集规则
-
字段匹配名称: 在采集(测试)时,显示值的名称,用于标注当前列的值的含义;
-
字段匹配规则:
-
映射类型: 根据采集内容类型选择
-
字段匹配:字段匹配规则选择的是"默认",此处填写默认值;否则填写对应匹配方案的匹配规则
-
关联表列名:此列配置对应当前采集任务导入表中的哪个字段
-
结果替换规则:对采集到的结果使用freemarker语法做二次处理;
-
内置参数:${content} 为当前列采集匹配到的内容;${app} 获取app实体的属性;
-
二次处理演示:
截取采集内容50的长度eg:<#if content?has_content>${content[0..50]}..</#if>
输出yyyy-MM格式的时间eg:<#if content?has_content><#assign content=content?date("yyyy-MM-dd")/> ${content?string("yyyy-MM")}</#if>
freemarker语法请参考freemarker文档
-
-
列表规则:开启后,推荐使用xpath匹配规则,并且只作用于列表
-
html内容:开启后,会检测当前匹配的内容是否满足html格式,不满足不会采集
Tip
列表规则的采集配置需要添加上对应内容链接的值,如通过xpath匹配列表中对应内容的图片//a[@href="{}"]/img/@src,{}为内容链接的占位,会自动处理
- 采集日志
- 采集匹配规则

- 导入采集数据