采集演示
- 新建采集任务 以文章采集为示例
- 配置采集规则 页面一般分为三种形式
- 列表是静态、内容是静态
- 列表是json、内容是静态
- 列表是json、内容是json
- 初始化文章上下篇关联数据
- 运行采集
- 采集测试 点击测试模拟采集,校验规则是否正确
- 启动采集规则 根据自动导入配置决定是否即时导入数据
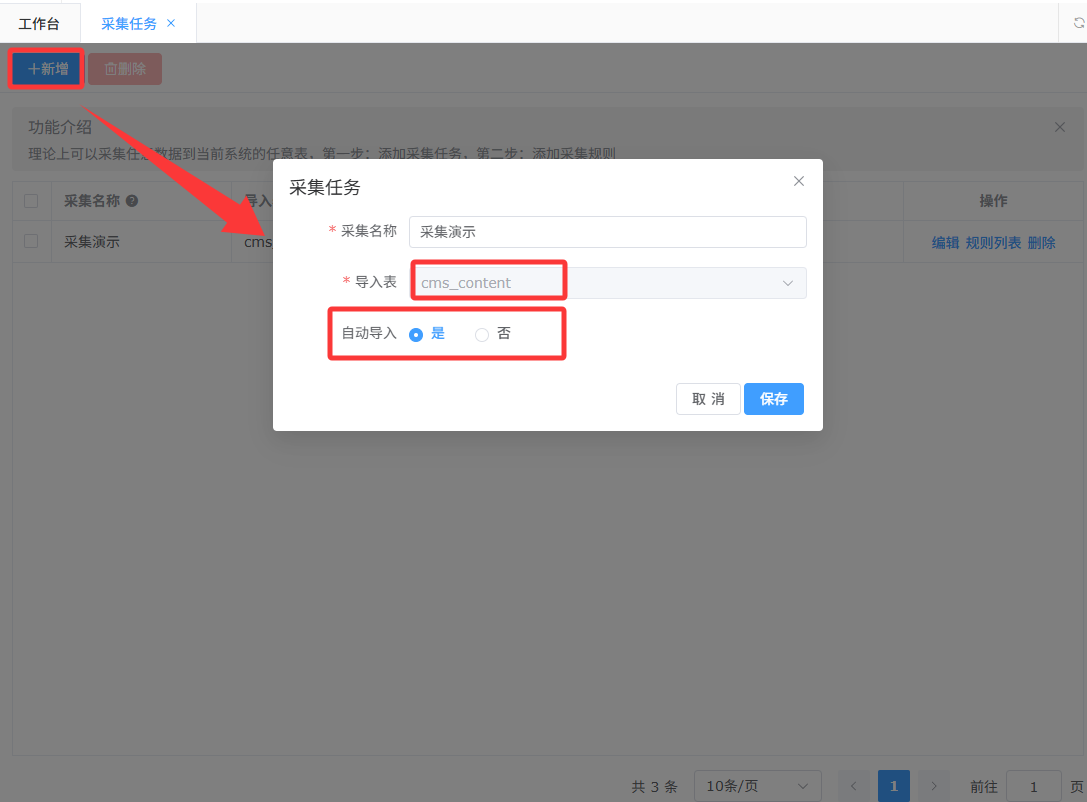
新建采集任务
以文章采集为示例
- 配置导入表:选择文章表(cms_content)
- 配置自动导入 :选择是,采集成功后自动导入到cms_content表中;选择否,采集成功在采集日志中手动选择采集到的数据导入
配置采集规则
列表是静态、内容是静态
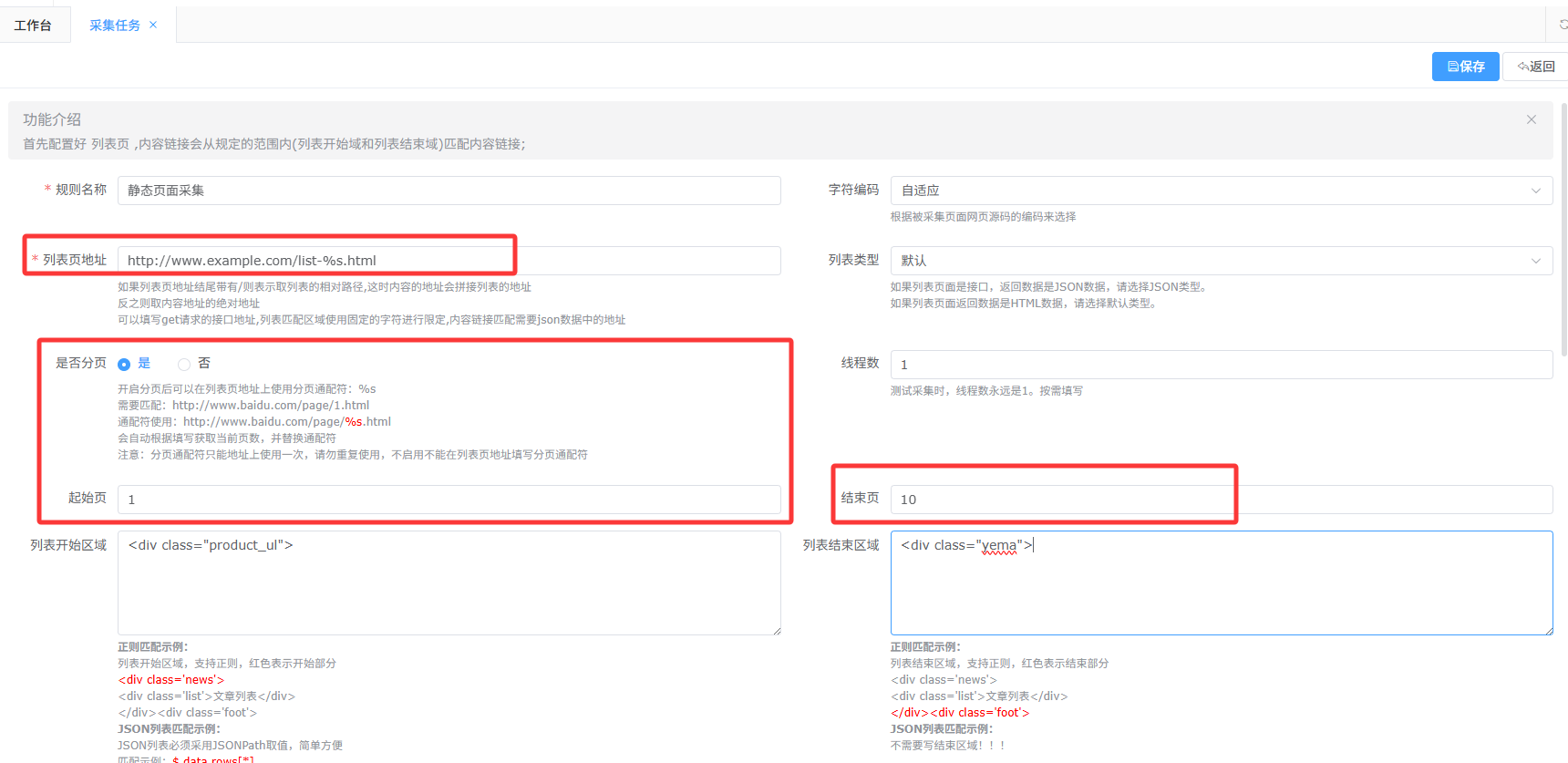
- 配置列表页地址
一般列表是带分页的,观察列表页面地址规律,使用```%s``替换具体页号
例如:列表页面地址为http://www.example.com/list-页号.html
因为列表带分页,所以配置时先开启分页,设置采集的起始与结束页号,列表页面地址配置成http://www.example.com/list-%s.html,其中 %s为分页占位符,采集时会替换成从起始页到结束页之间的连续数字
-
特殊分页场景说明
-
如果列表第一页地址为:http://www.example.com/index.html,后续页面地址为http://www.example.com/list-页号.html。此时需要分两次进行采集,两次采集只需更换列表页地址和分页配置
-
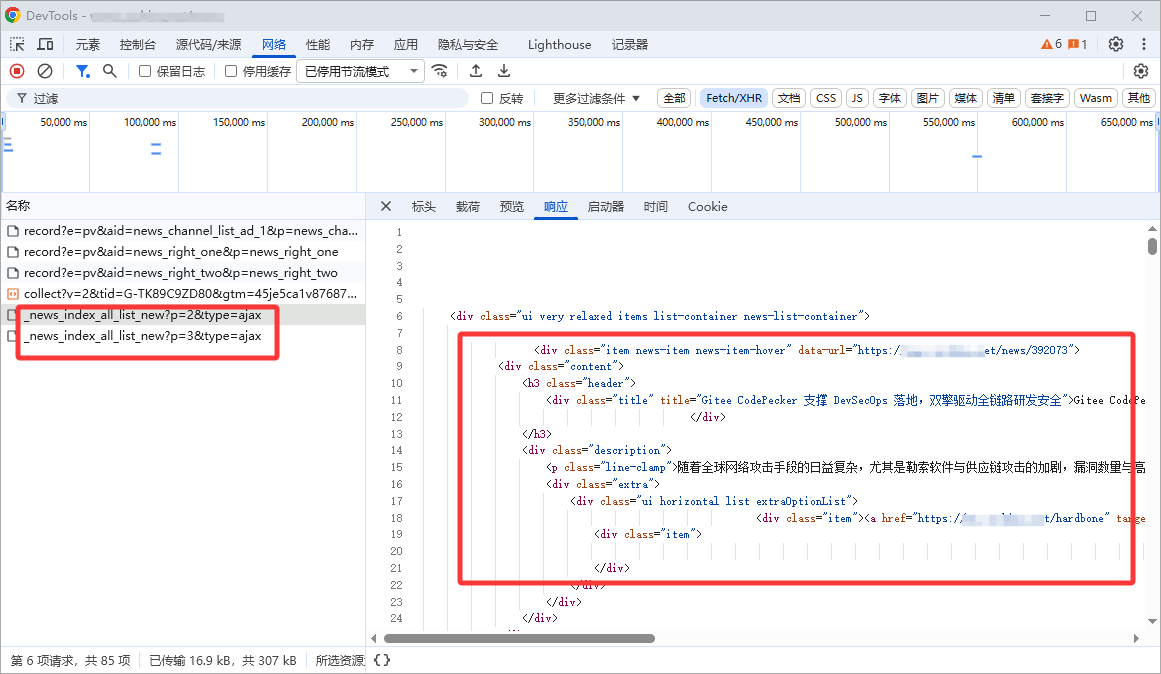
如果列表页面是以AJAX请求获取页面内容,并动态追加到DOM中。列表页地址则配置请求的接口,列表类型选择默认,其余与静态列表页面配置一致
如下图,列表页地址:https://www.example.com/_news_index_all_list_new?p= %s&type=ajax
-
-
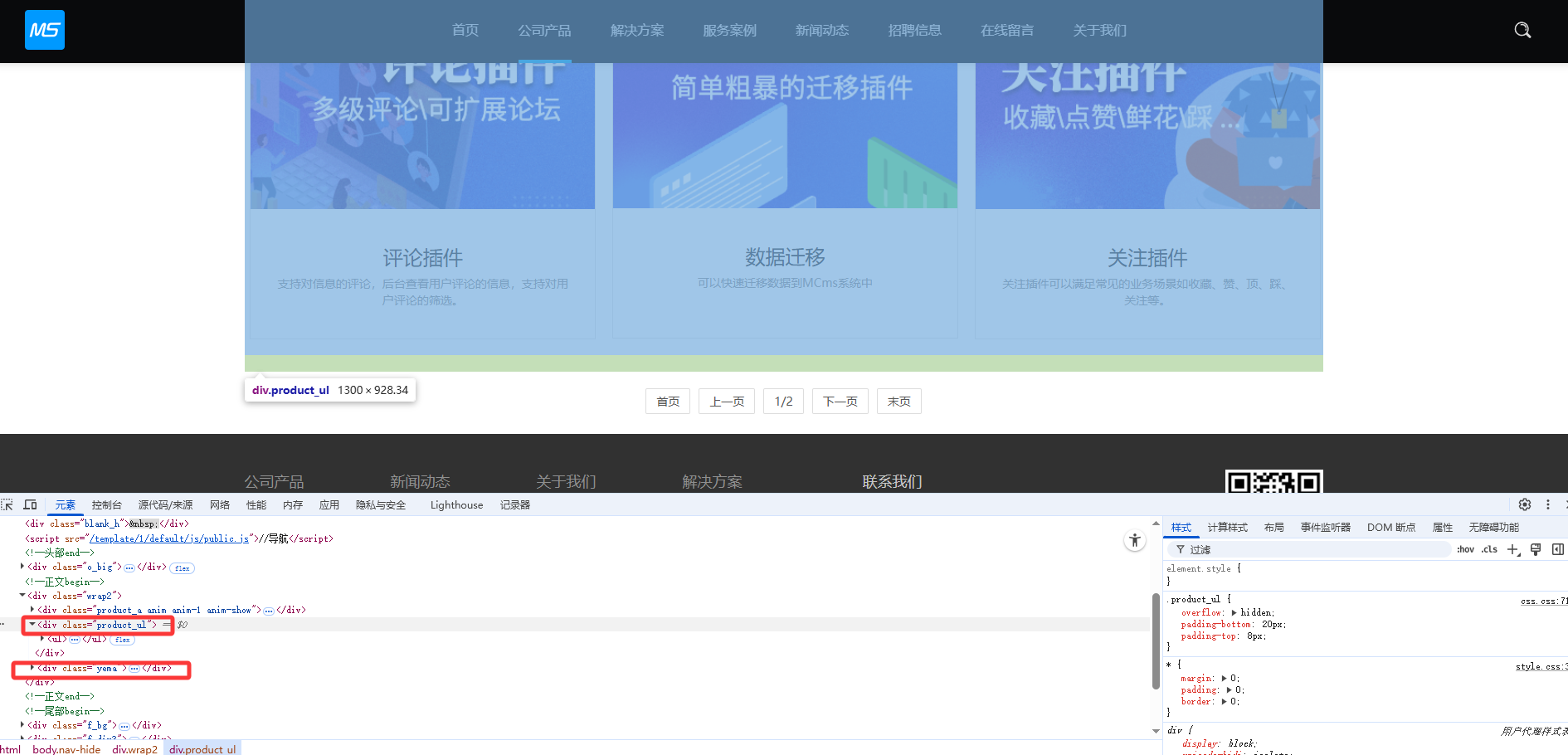
配置列表采集区域
通过F12打开控制台,找到列表页面初始区域,如图起始区域为<div class="product_ul">; 结束区域因为div不能唯一确定,所以选择下一个区域的开头作为起始区域,此处为<div class="yema">
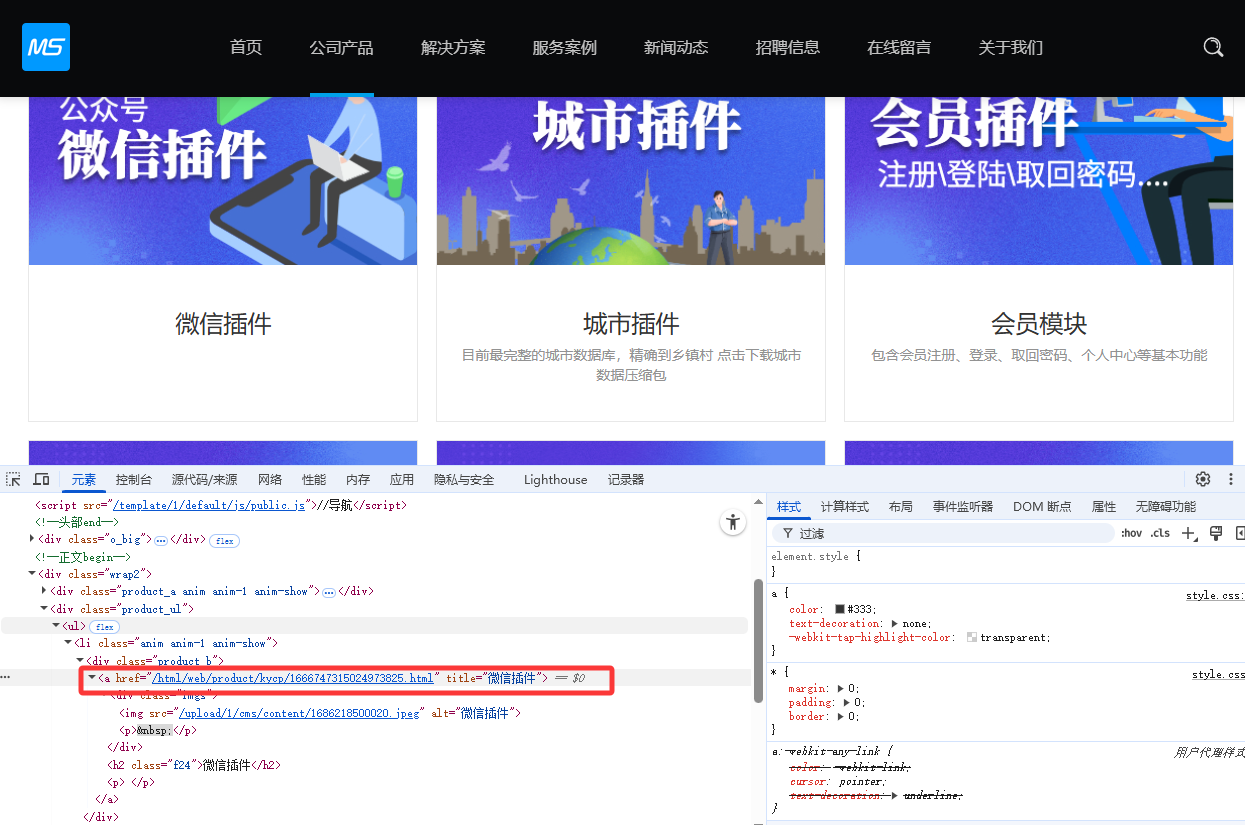
- 配置内容链接匹配规则
如下图:文章地址 可直接通过正则匹配
href="(.*?)"
Tip
注意:需要用()把链接地址包裹起来,不然会出现匹配链接不全的问题
-
配置字段匹配规则
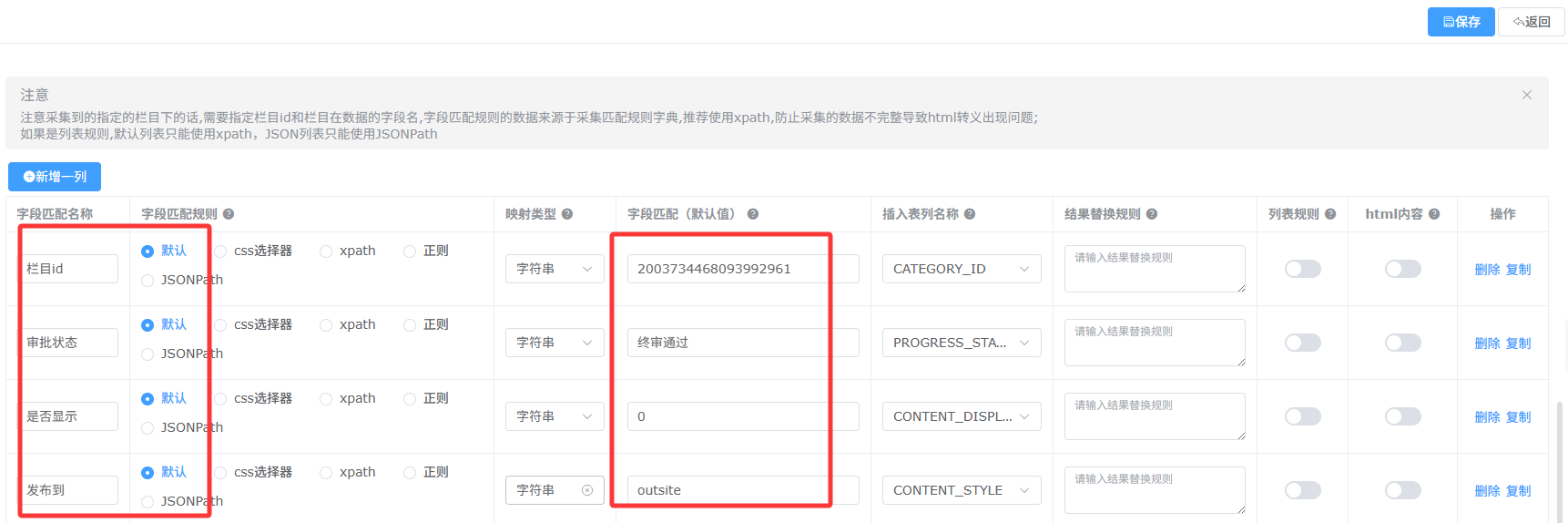
- 默认值字段
以下列举几个常见的默认值字段配置。字段匹配规则选择默认
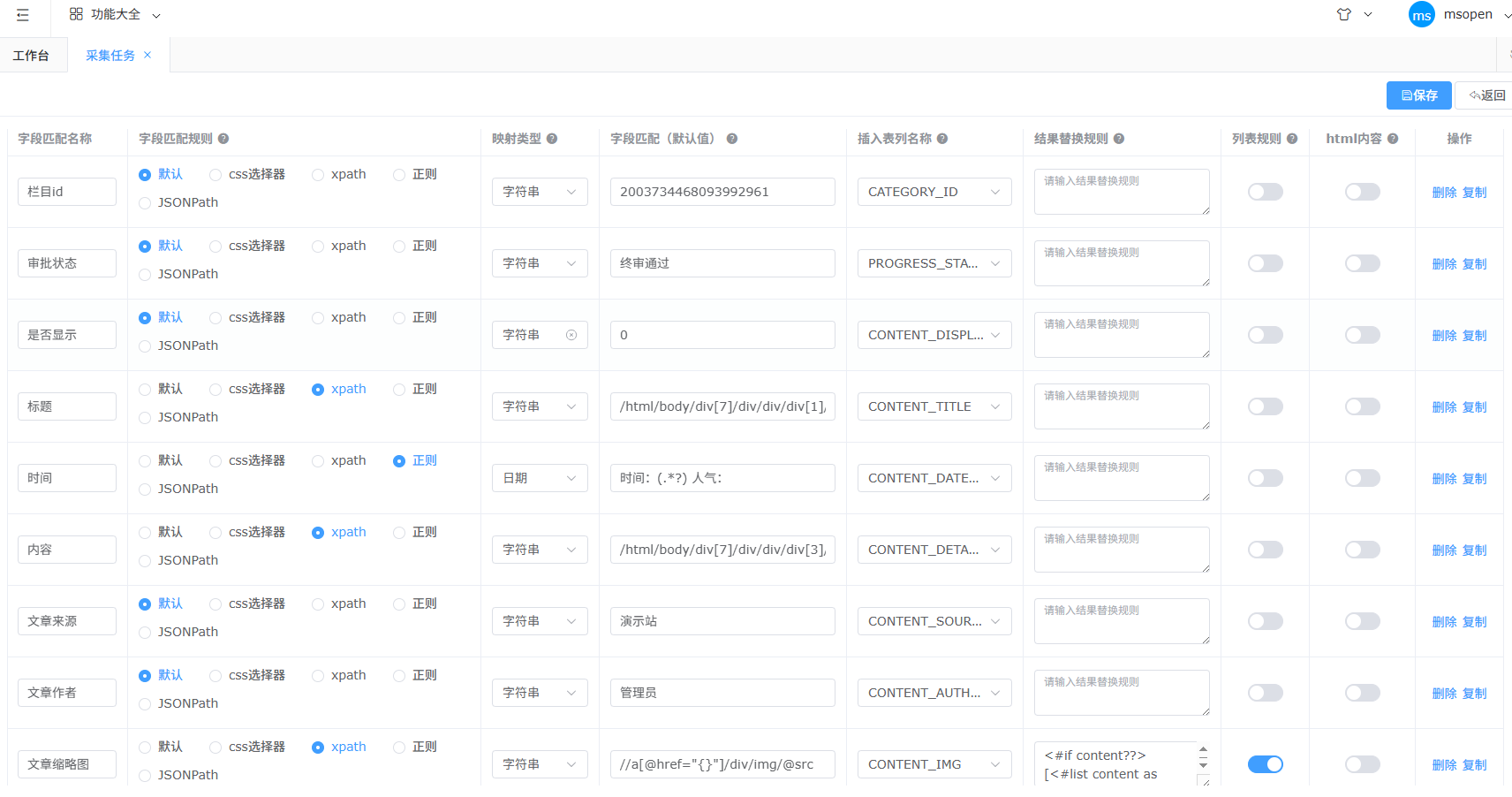
栏目id 配置前需手动新增采集的栏目,再将栏目的id填写到字段匹配(默认值)中,对应数据库字段 CATEGORY_ID
审批状态 (终审通过/草稿)推荐设置终审通过,对应数据库字段 PROGRESS_STATUS
是否显示(0显示/1不显示)推荐设置0,对应数据库字段 CONTENT_DISPLAY
发布到 (outsite外网,insite内网)设置的默认值由当前绑定的模板决定 对应数据库字段CONTENT_STYLE
- 其他字段
详情页面的字段信息一般是最完整的,优先从详情页面获取字段信息;当在详情页面无法获取时,才使用列表规则匹配,如文章缩略图字段
需采集的字段建议优先使用xpath 匹配; 无法处理时才考虑正则匹配
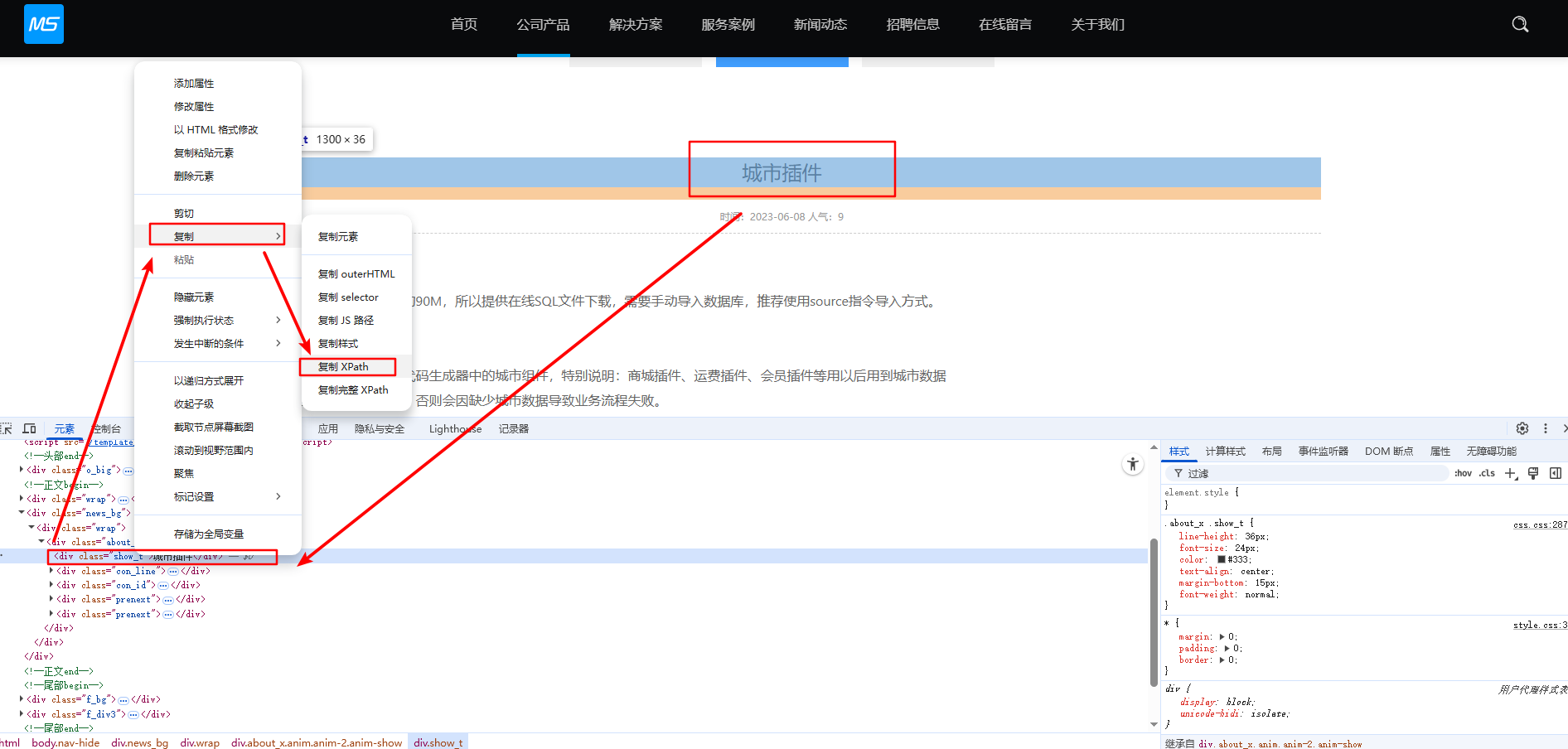
xpath使用技巧 在控制台中选择需要匹配的区域,右键选择复制xpath
以下列举几个常见字段匹配规则分析
文章标题 目标div结构只有一个标题,直接使用xpath获取,xpath路径追加 /text() 用于取文本内容,对应数据库字段 CONTENT_TITLE
文章内容 目标div结构内为文章内容,直接使用xpath获取,xpath路径追加 /html() 用于取内部完整html结构,对应数据库字段 CONTENT_DETAILS
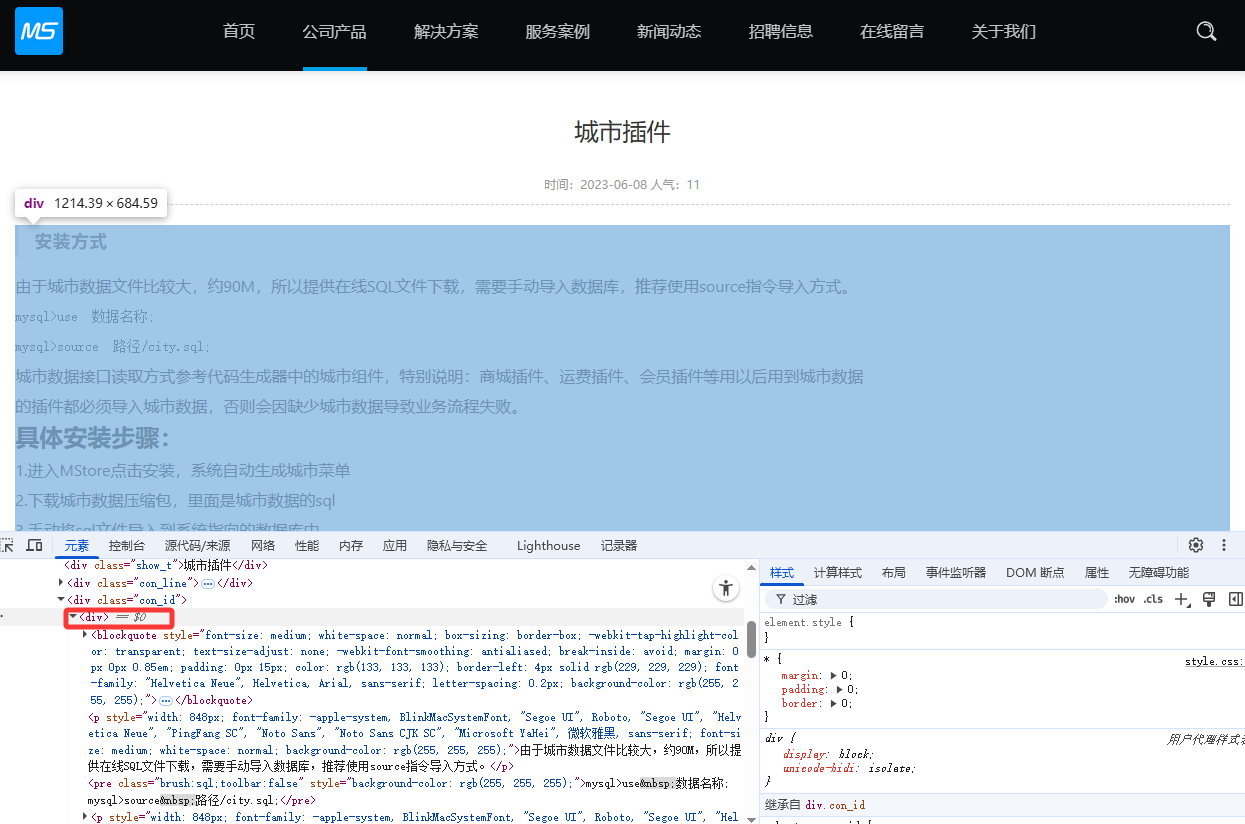
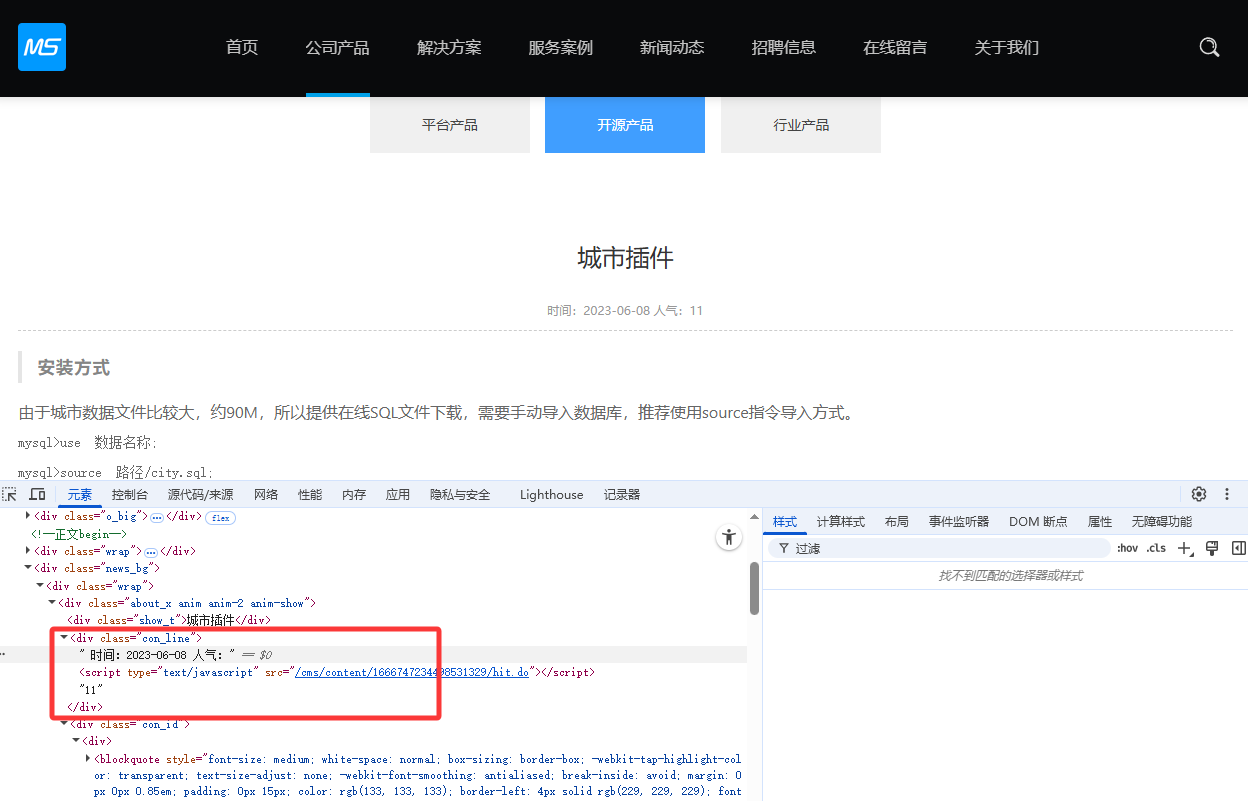
发布时间 分析结构,div内包含时间和人气两部分,通过xpath无法定位具体时间值,此处采用正则处理,表达式:
时间:(.*?) 人气:(.*?)匹配到的值会存进数据库,如下图会将2023-06-08存入数据库
注意选择日期类型,对应数据库字段 CONTENT_DATETIME
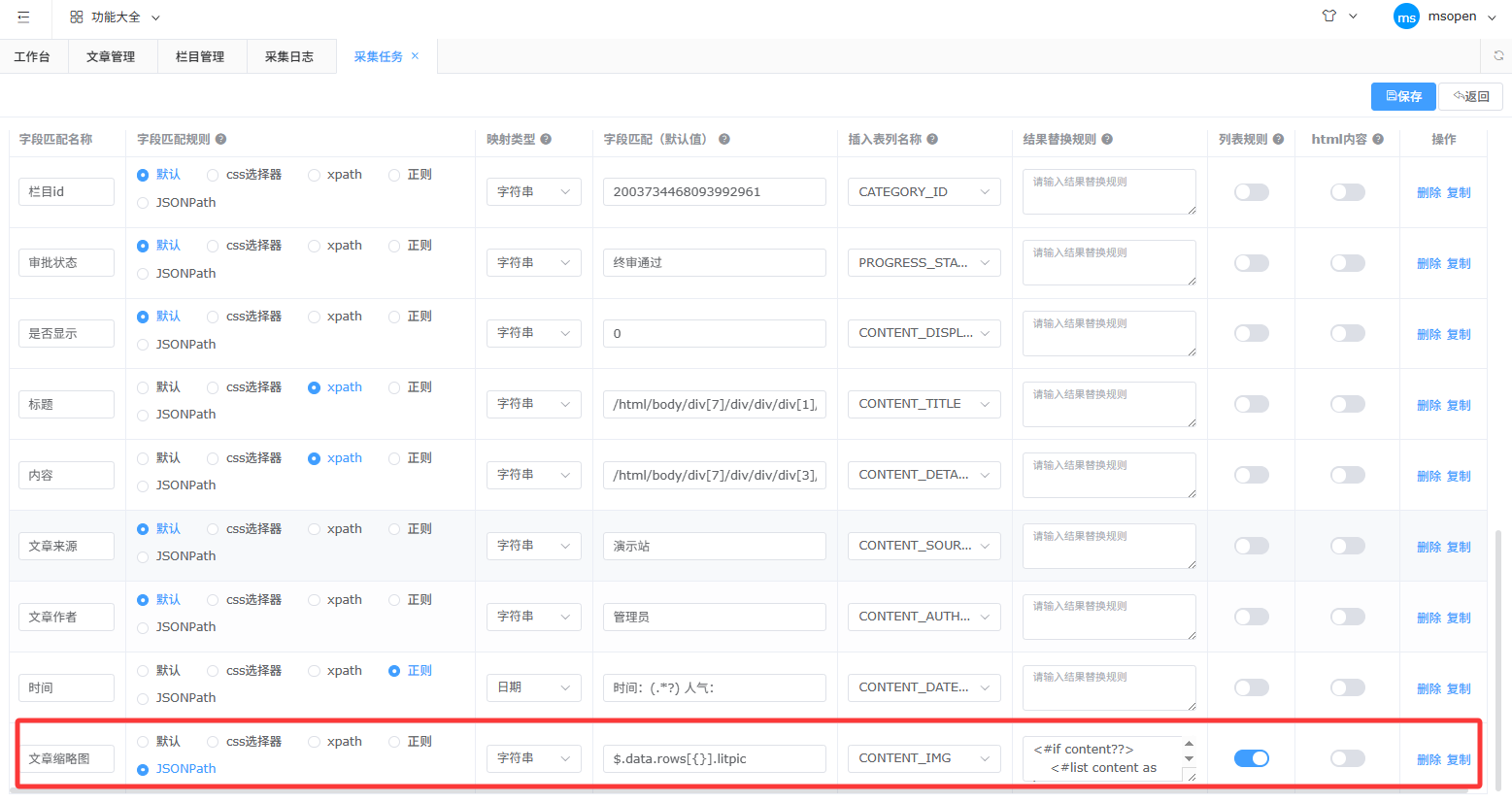
文章缩略图 缩略图一般在列表中展示,此处选择列表规则匹配,一般通过xpath匹配图片
如图缩略结构a/div/img

故xpath规则如下,其中//a表示选择a标签;{}为占位符,区分不同的文章详情的链接地址,唯一确定图片属于哪篇文章;@src表示取图片的src属性
//a[@href="{}"]/div/img/@src 其中//a[@href="{}"]/.../img/@src 一般为固定结构,中间的结构(...)可自行修改注意系统的图片格式是以json数组存储,即:[{"url":"xx.png","uid":"xx"}] ;还需要在结果替换规则里将图片路径组织成json数组,可直接复制下面转换模板
<#if content??> [<#list content as img> <#assign url=img?substring(img?last_index_of("/")+1)> {"url":"/upload/${app.id}/content/${url}","uid":"${url}"} </#list>] </#if>
Tip
采集的图片默认存放在本地目录upload/站点id/content目录下,修改默认目录参考:修改采集的图片存储目录
以下为完整字段示例
列表是json、内容是静态
- 配置列表页地址
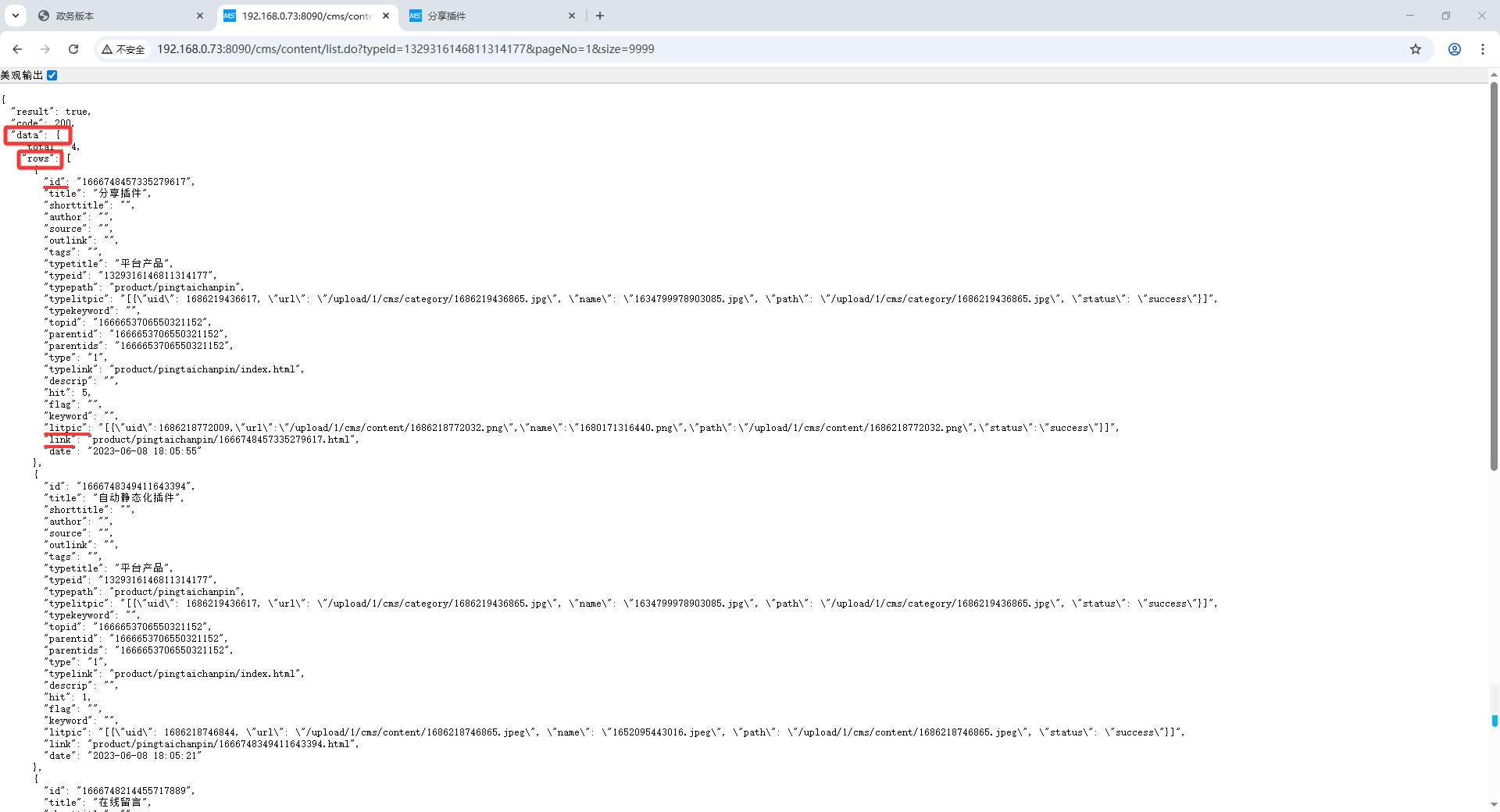
列表数据是动态渲染的,所以配置列表数据请求接口,如文章列表地址:http://192.168.0.73:8090/cms/content/list.do?typeid=1329316146811314177&pageNo= %s&size=20
列表类型选择json,分页选择是,配置起始页和结束页,分页占位符 %s会自动替换成起始页到结束页之间的连续数字,页号、每页文章数量、采集数量根据页面接口灵活配置。
- 配置列表采集区域
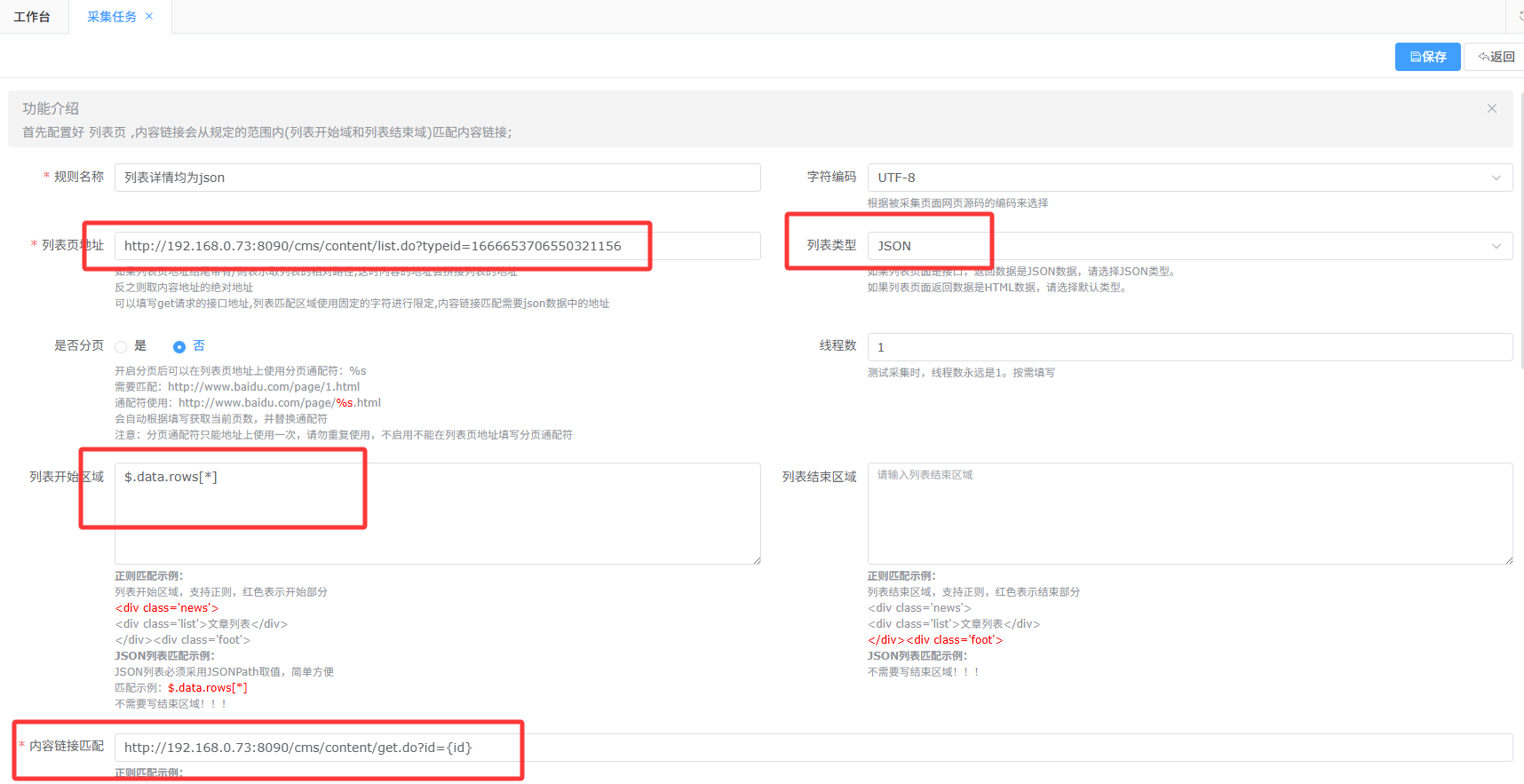
列表区域填写列表数据返回目录,如图为data/rows,目录开头加$,结尾加[*],字段加. ,所以列表开始区域填写 $.data.rows[*],不需要写结束区域
- 配置内容链接匹配规则
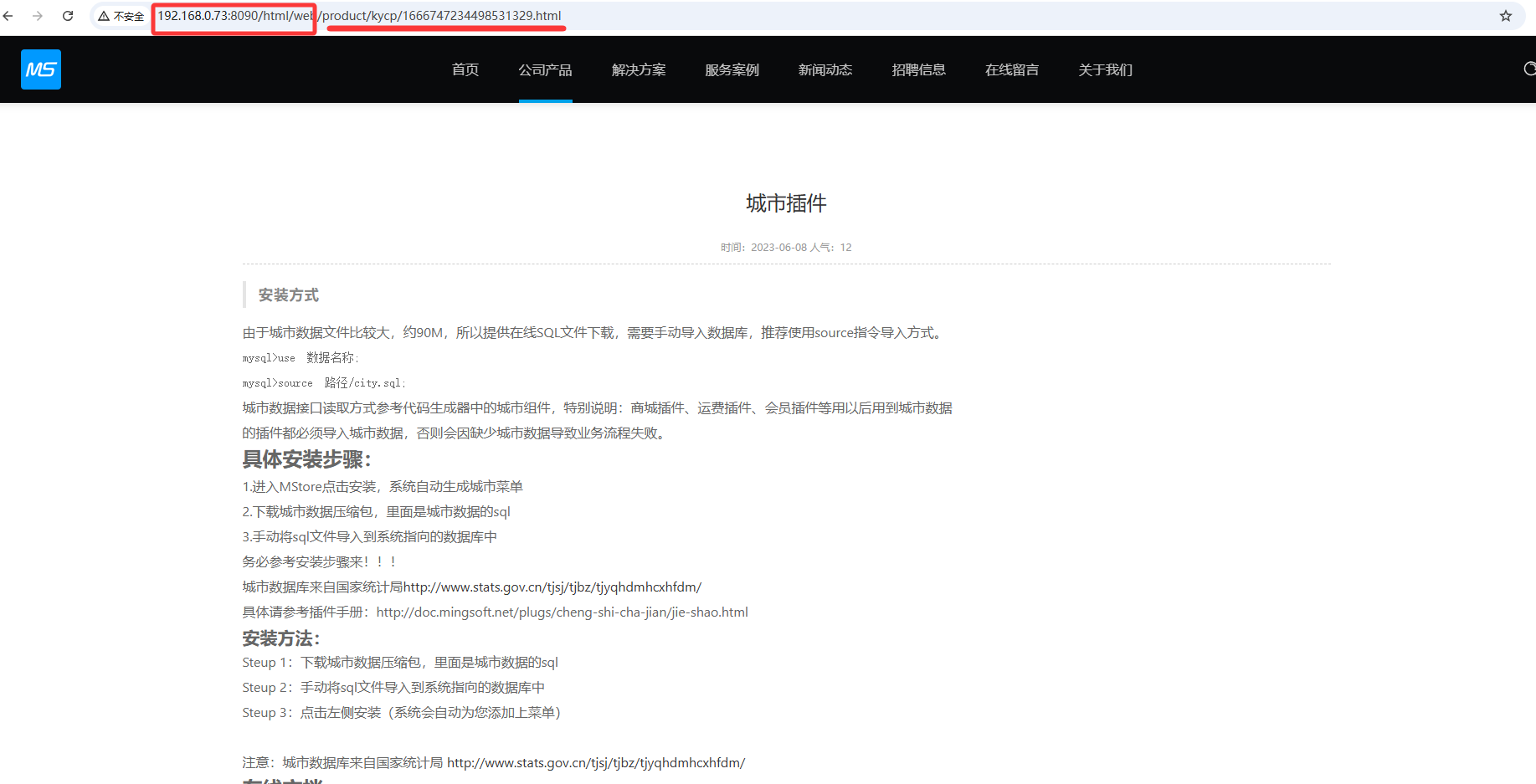
如图目标地址有两部分 http://192.168.0.73:8090/html/web/ + 路径,上图列表json数据已经返回了路径
所以内容链接匹配为: http://192.168.0.73:8090/html/web/{link} ,link为上述data/rows数组中的值,数组中的值可直接通过 {} 取
- 配置字段匹配规则
因为文章详情页是静态的,故文章详情页中的字段取法参考上述列表是静态、内容是静态
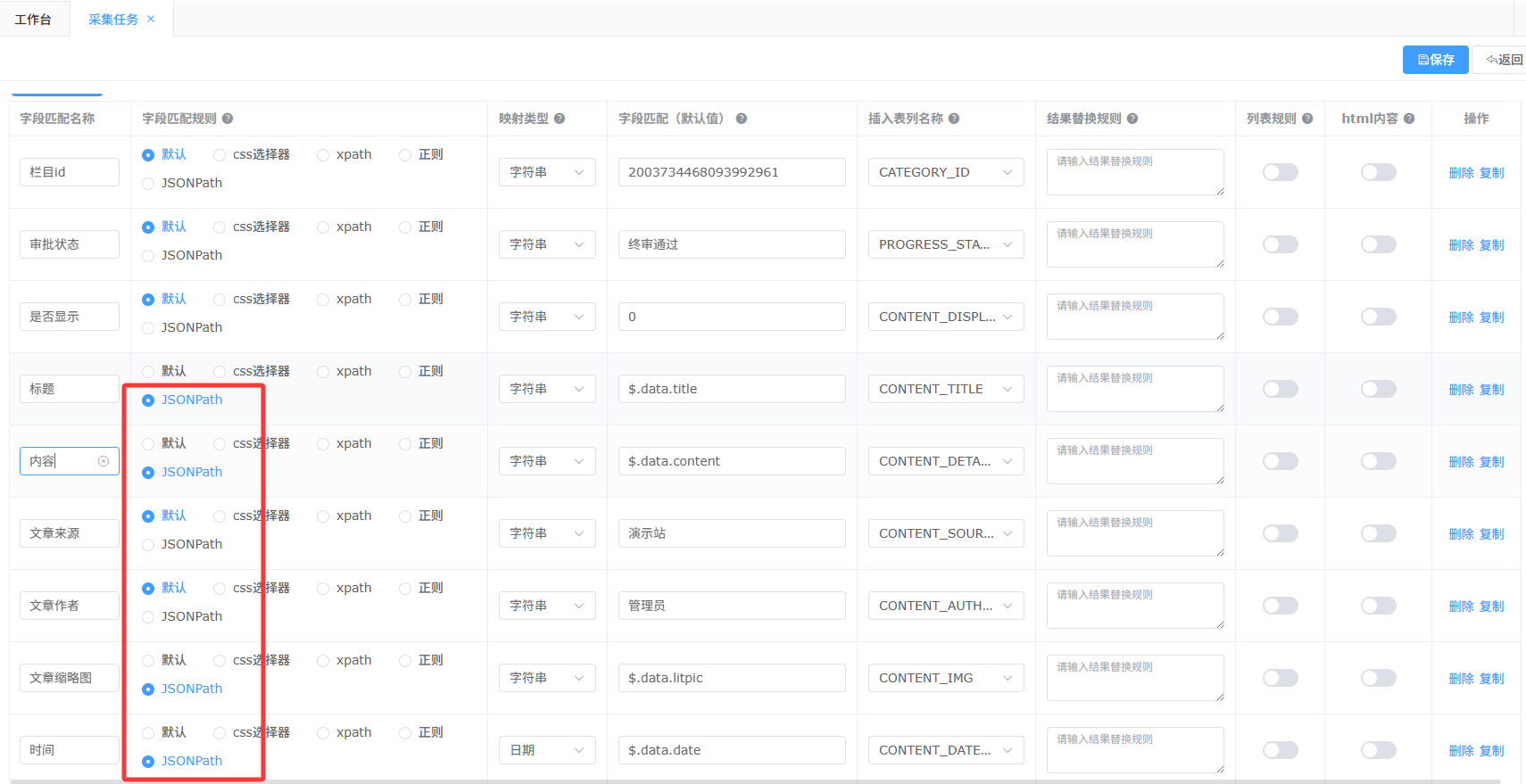
文章缩略图 缩略图在列表页,此处通过JSONPath获取缩略图
$.data.rows[{}].litpic
其中$.data.rows[{}] 为上述文章列表数据返回的结构,中间的 {} 为占位符,唯一确定图片属于哪篇文章,litpic为文章缩略图 字段
注意:开启列表规则,则content(匹配的值)的类型为集合类型; 如果对参数二次处理,通过list遍历组织参数
如下缩略图目标结构为[{"url":"xx.png","uid":"xx"}] ,而上述例子返回的图片路径为json数组结构,故通过JSONPath取属性会变成[ [{"url":"xx.png","uid":"xx"}] ],需要配置 结果替换规则组织路径,如下:
<#if content??>
<#list content as img>
${img}
</#list>
</#if>
结果替换规则基于freemarker语法,可对采集到的值灵活的二次处理
以下为完整字段示例
列表是json、内容是json
- 配置列表页地址、采集区域
参考上述列表是json,内容是静态部分
- 配置内容链接匹配规则
填写详情页面数据请求接口,例如:http://192.168.0.73:8090/cms/content/get.do?id= {id}
其中id为列表数据返回的字段
- 配置字段匹配规则
以下只介绍差异部分,如图为文章详情页面接口返回的数据
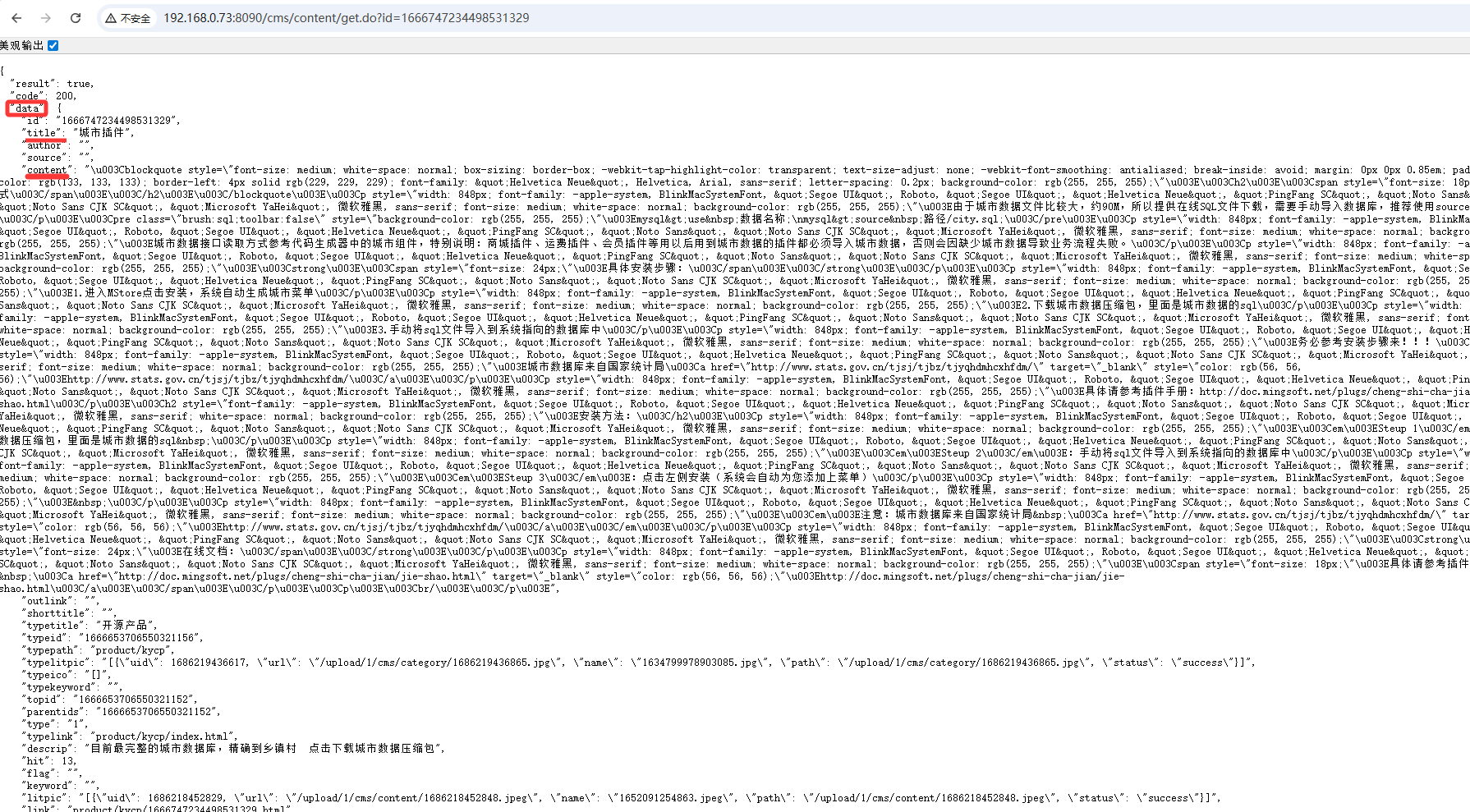
在详情页的属性可通过 $.对象名.属性名 获取
如文章标题: $.data.title
文章内容: $.data.content
以下为完整字段示例
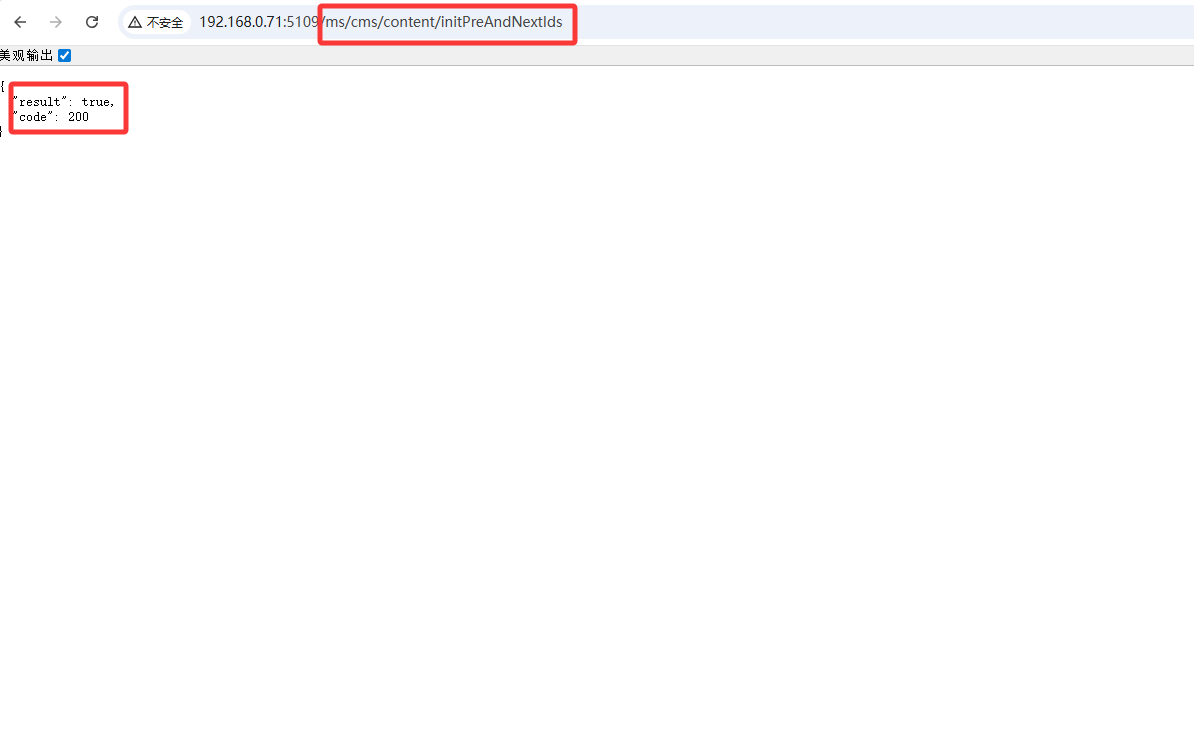
初始化文章上下篇关联数据
首先登录后台,再调用 http://ip:port/ms/cms/content/initPreAndNextIds 接口
返回true则初始化成功
运行采集
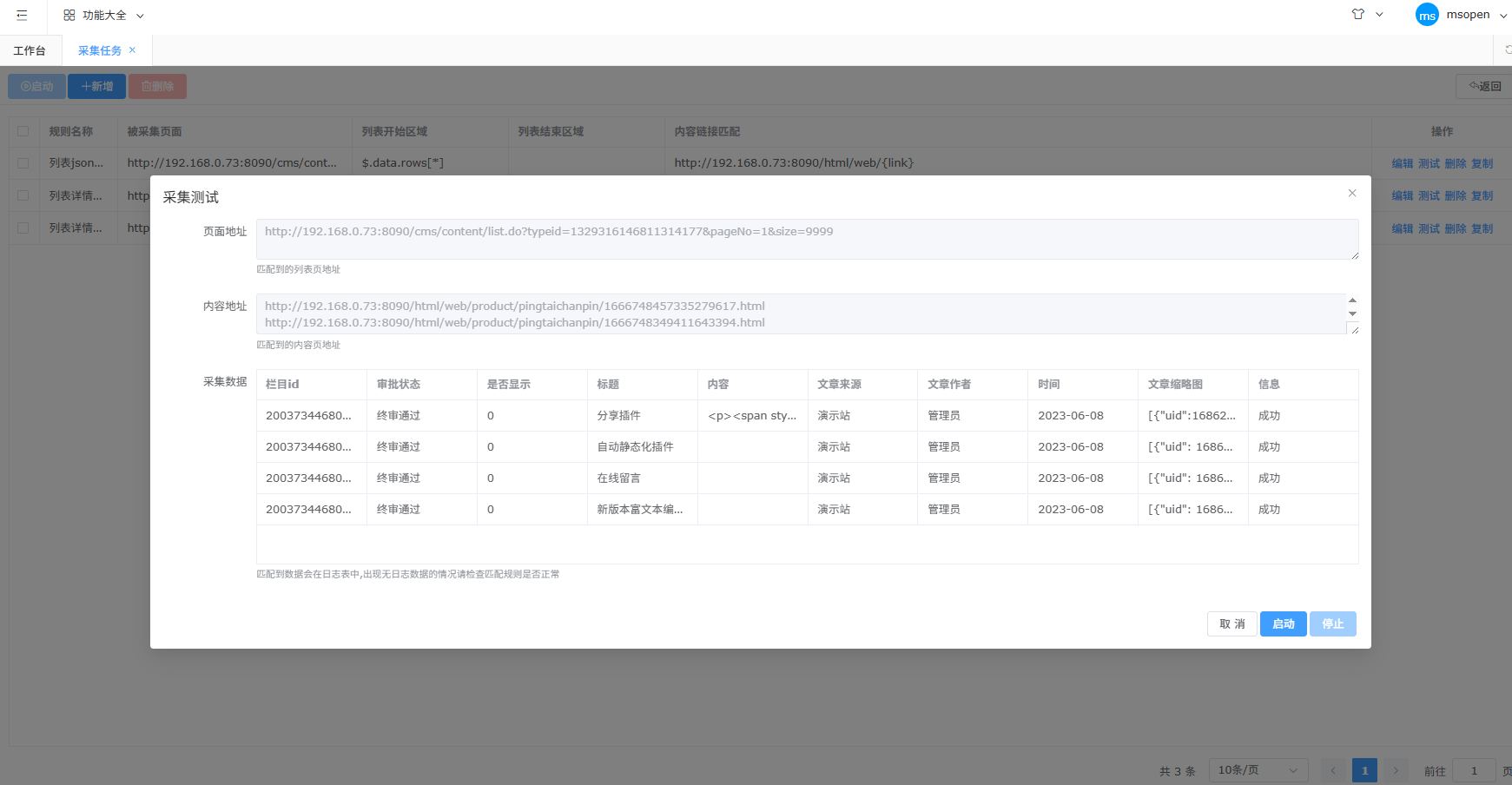
采集规则测试
规则新增好后,在规则列表里点击测试按钮模拟采集,观察规则是否生效、采集的数据是否正确。
Tip
注意:采集测试不会产生采集日志,更不会将数据导入配置的表中,仅用于验证采集规则的正确性。
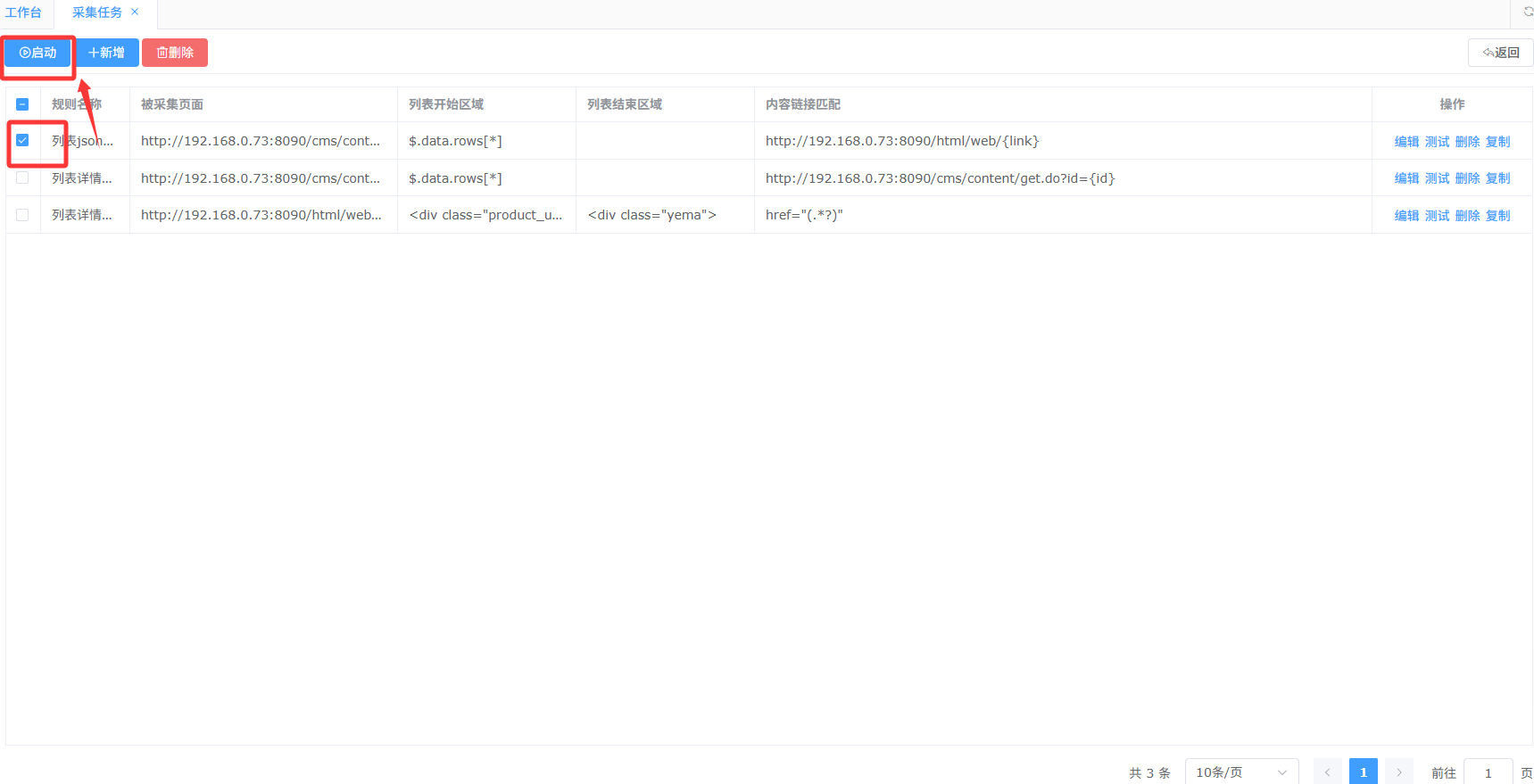
运行采集规则
选择需要运行的规则,点击启动,当采集任务是自动导入时,采集的数据会自动导入到配置的导入表
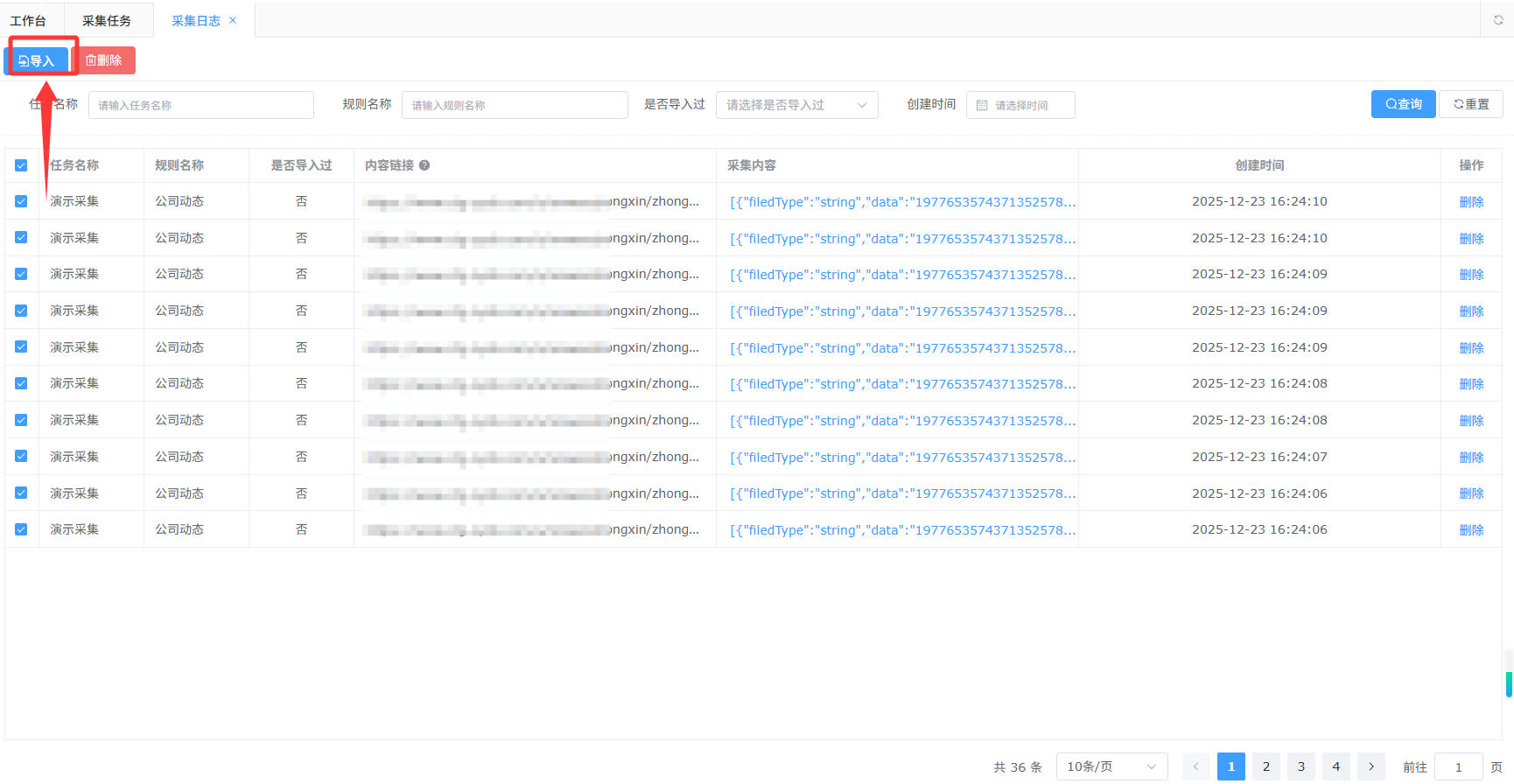
如果不是自动导入,需要在采集日志中手动选择需要导入的数据
Tip
之前已经采集过的页面,系统不会重复采集;如果需要重新采集,请先删除之前采集日志,再重新采集